Next: 8 Detailed Design Process Detailed Description Up: Appnotes Index Previous:6 System Design Process Detailed Description
![]()
![]()
![]()
![]()
Next: 8 Detailed Design Process Detailed Description
Up: Appnotes Index
Previous:6 System Design Process Detailed Description
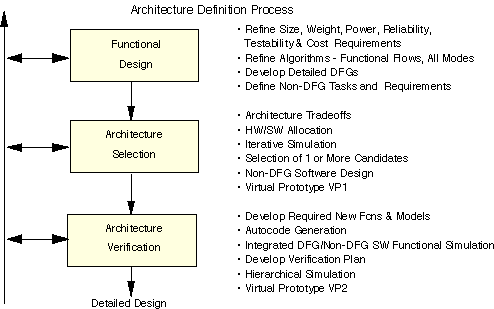
The functional design step provides a more detailed analysis of the processing requirements, resulting in initial sizing estimates, detailed data and control flow graphs for all required processing modes to drive the hardware/software codesign, and the criteria for architecture selection. The control flow graphs provide the overall signal processor control, such as mode switching (referred to as the command program). Functional simulators support the execution of both the data and control flow graphs. For complex control applications, these simulations can be coupled to ensure that all control is properly executed and results in the proper graph actions (e.g. mode transitions).
During architecture selection, we evaluate various candidate architectures through iterative performance simulation and optimize them to appropriate levels of detail. A trade-off analysis based on the established selection criteria results in the specification of the detailed architecture, and software partitioning and mapping. As part of the trade-off analysis, we use information from as many disciplines as possible (either manually or through design advisors) to populate the trade-off matrix. This portion of the process is heavily dependent on the reuse of architectural (hardware and software) components to provide significant time-to-market improvements. In addition, during architecture selection, we design all software not represented by the DFGs. Based on the requirements, the non-DFG software may include BIT, downloading, and diagnostics. The virtual prototype, VP1, produced during architecture selection is not a full system prototype, since function and performance are simulated independently and may or may not be coupled with the overall control mechanism.
During architecture verification, we develop the next level of detail for one or more architectures that meet the requirements and satisfy the established selection criteria. We develop and validate any required library elements (either hardware or software) at this time if they are not completed concurrently. Autocode generation is performed for the DFG based software, and the non-DFG based software (particularly the command program) is developed. The next level of performance simulation should include timing estimates for the generated code, along with a representation of the operating system services, scheduling, and run-time system overhead. We generate a hierarchical validation plan that ensures that all component interfaces are tested. Detailed hierarchical simulations are performed to verify both functionality and performance on the target architecture. The virtual prototype, VP2, produced during architecture verification, represents a functional and performance description of the overall design.
The arrow on the left side of Figure 7 - 1 indicates that the process has feedback within the architecture definition process, between the architecture and systems processes and between detailed design and the architecture processes. In fact, as shown in Figure 4 - 2, various portions of a design may be at different levels of maturity, which implies that more than one of the processes may be active concurrently. Note that as a design progresses, new development activities (mini-spirals) may be initiated. For example, during functional design it may be perfectly obvious to the designer that:
A hardware and software component reuse library has models and data at various levels, as shown in Table 7 - 1. These models support concurrent codesign throughout the selection and verification process. The reuse library drives both the architecture synthesis and the software synthesis processes in an integrated fashion.
The following sections describe the steps in the architecture definition process.
nputs to this portion of the process are the outputs of the system design activity. These include both signal processing requirements and physical requirements. The signal processing requirements include the algorithm flows for all modes of operation, the control flows (if any) used to control the initiation of processing modes and the transition between modes, and performance timelines which must be met. The physical and/or programmatic requirements include the size, weight, power, reliability, testability, cost, and schedule.
Outputs from this portion of the process include prioritization of the implementation requirements, the library-based DFGs representing the processing for each operational mode, software requirements for non-DFG processing (e.g., mode switching), and definition of the criteria and weighting used to select the architecture. Note that the selection criteria may be just as sensitive to cost and schedule as it is to performance.
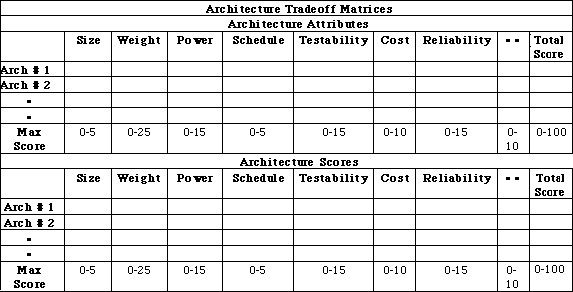
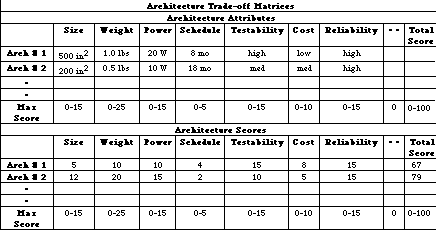
We define a trade-off matrix to formalize the selection criteria for the architecture, as shown in Figure 7 - 3, which contains the top-level requirements allocated to the signal processor. Satisfying these requirements drives the hardware/software codesign of an architecture. We populate the matrix and iteratively update it as any given design progresses. Early in the process, the entries are less accurate than later on. The goal is to eliminate some designs early while carrying the best candidates to subsequent levels of detail. The entire Integrated Product Development Team (IPDT) has rapid access to the ongoing trade studies and participates in populating the trade matrix through various tools and design advisors. Once we have established the criteria, we develop its relative weighting for the particular application to ensure that the proper emphasis between performance, cost, schedule, and risk is reflected in the architecture selection. We use these weighted criteria to drive both the architecture selection and the level of optimization and effort that is applied during this portion of the design. The exact content of the trade-off matrix and the maximum scores associated with different attributes is project dependent.
The DFGs are the basis for both the architecture synthesis, the detailed software generation, and potentially custom processor synthesis. As indicated in Figure 7 - 4, validating the DFG is an important step that ensures consistency with the simulatable requirements passed down from the systems process. The left side of the figure represents a processing flow that has been simulated during systems definition to establish the baseline algorithm set for the application. If multiple processing modes are required, there would exist a processing flow for each mode. The right side of the figure represents the detailed PGM DFG constructed from reuse library elements.
The examples used throughout the rest of this section will use PGM graphs as their basis. More information regarding GEDAE™ data flow graphs may be found in the Hardware/Software Codesign application note, the Data Flow Graph Design applicaton note, or the GEDAE™ web page at http://www.gedae.com.
Each detailed DFG is simulated to provide data for comparison with the algorithmic flows developed during the systems process. As part of this simulation process, the DFG may require modification until the correct functional results are achieved. Validating these two representations ensures that the simulatable functional requirements are captured in the DFGs that will drive subsequent codesign.
In some cases a suitable library component may not exist, which means designing either a hardware or software element. For software, this is referred to as a prototype element. The prototype element will permit the hardware/software codesign to proceed before validating the element for permanent inclusion in the reuse library. For hardware, a similar prototype is established by generating a high-level performance model (see the Token-Based Performance Modeling application note) of the desired component. In either case, the architecture process can proceed using estimates for these elements.
In addition to the DFG generation, the control flow requirements are transformed into the control flow graphs (CFGs)(see the Autocoding for DSP Control application note) required to manipulate the DFGs according to a defined set of rules. This DFG control is referred to as command processing. Command processing is needed to incorporate signal processing into the overall system design. The signal processing functionality needs to be controlled in accordance with the other functionality dictated by the system design. The mechanism that exercises this control over the signal processing subsystem is the command program. The signal processing subsystem receives messages from the external environment and commands the signal processors to perform their detailed function. The command program performs the control operations of the signal processor subsystem. While DFGs describe the functionality associated with the signal processing subsystem, the command processing function is best described by an object-oriented methodology. The design of the two are interrelated, since design of the DFGs must provide access to or the ability to set graph parameters as dictated by the command program. Consequently these designs must be performed concurrently.
When we develop the signal processor code using the PGM or GEDAE™, a set of operators are needed to control the resultant functionality. The signal processing graphs and their data structures are objects manipulated by the command processing program. The operations upon these objects have to be executed in both realtime and non-realtime. For example, we can initialize the primitive node and the resultant data structures in non-realtime. However, operations such as starting the I/O operation, disabling queues, mode changing, changing dynamic parameters, etc. are all realtime operations and are often specified by commands external to the DFG operation. The command program facilitates interface of the signal processor subsystem to the rest of the overall system. As part of the functional design, the detailed specification of these non-DFG processing requirements is completed. Conceptually, the command program manipulates objects. The objects are the DFGs and their data structures. The top-level requirements define a set of actions that have to be performed by these objects. The designer must specify the actions associated with each of the states of these objects, both for the normal and abnormal conditions. This information will be contained in a state model. Associated with all the states is a process model that expresses the procedures to be executed at each state.
The architecture selection process, shown in Figure 7 - 5, represents the heart of the RASSP hardware/software codesign, which uses a library-based, DFG-driven approach to software development combined with iterative performance trade-off analysis to support rapid selection/analysis of candidate architectures. During architecture selection, various architectures are offered as candidates that are selectively optimized. For each candidate, the process includes the following steps:
We use a trade-off analysis based on the established criteria to select the detailed candidate architecture and software. Architecture selection is iterative and intended to produce one or more architectures that meet the overall requirements. Ideally, we evaluate candidate architectures that span the design space.
Inputs to the architecture selection process are the prioritized processing requirements, the selection criteria, the required DFGs for all modes of operation, command program specification and other non-DFG requirements, and the hardware/software reuse library.
Outputs from the architecture selection process are the finalized DFGs and one or more architecture instantiations that we selected for more detailed functional and performance verification. Also output from the architecture selection process is the description of the DFG partitioning and mapping to the processors of the selected architecture(s) for all processing modes.
The steps involved in architecture selection shown in Figure 7 - 5 are discussed below.
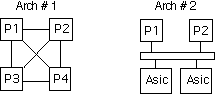
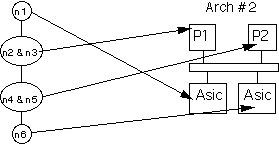
Given the DFG (or set of DFGs) that describes the processing, the architect must postulate one or more designs that may satisfy the requirements. These architecture choices are based upon the domain experience of the design team. One of the goals of RASSP is to facilitate the ability to define and evaluate more alternatives than would otherwise be possible. This is done through the use of the integration and semi-automation of the architecture tools that assist the DSP design architect. It is important to note that the processing represented by the DFGs at this point has not been allocated to either hardware or software. However, as the architect defines an architecture for consideration, one or more nodes of the DFG may be allocated to custom hardware or to a postulated processor that currently does not exist. Figure 7 - 6 shows two simple alternative architectures. In Arch #2, one or more nodes of the DFG have been allocated to either an existing or postulated special-purpose ASIC. In either case, the architect made a decision regarding hardware/software allocation. In Arch #1, all processing is performed in software on one of the four processors, while in Arch #2 some functions are constrained to the ASIC, while all others are allocated to software on one of the two processors. These architectures illustrate the point. In reality, the RASSP methodology must be capable of dealing with architectures that range from simple cases (such as those illustrated) to multi-chassis configurations of hundreds of processors. Architectures can be constructed from existing entities ranging from single processors to boards.
For the selected architecture type, we select specific processor type(s) (e.g., ™S320C40, i860, AD21060, etc.) and number of processors, along with a desired communication mechanism (e.g., bus, Xbar switch, etc.). We choose the number of processors based upon prior estimates of performance and/or validated benchmark data for library code fragments, and knowledge of the system requirements. We can perform a preliminary physical decomposition and do a high level study of routability, thermal issues, etc.
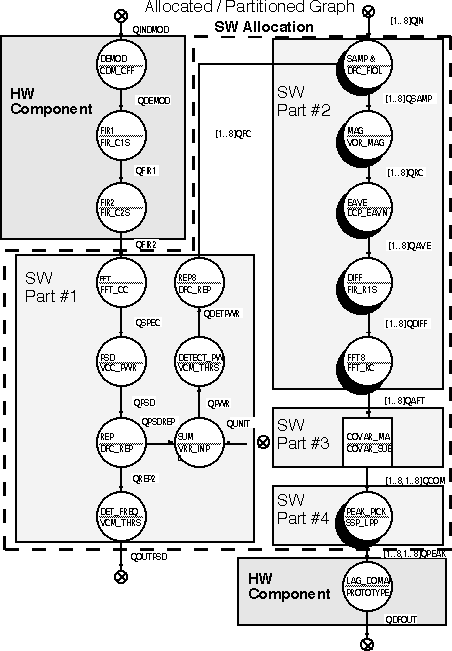
The portion of the DFG(s) allocated to software is partitioned and mapped to the available processors of the candidate architecture under consideration. The software partitions are defined by mapping the primitives in the DFG to the DSPs in the architecture. Figure 7 - 7 shows a DFG in which two portions of the DFG are allocated to hardware and the remainder of the DFG allocated to software grouped into four partitions. This activity is supported by multiple, automated partitioning/mapping algorithms for graph assignment and a manual capability. This process may utilize what -if experimentation to evaluate postulated architecture components, as well as software performance estimates for prototype primitives. In addition we postulate architectures for the non-DFG software. We construct a VHDL performance model for the architecture. It may be obvious that special-purpose hardware or a custom processor is required to meet the overall signal processor requirements. If so, we can start a mini-spiral development activity to embark on the required development. The performance of the new hardware may be estimated so that the overall architecture selection may proceed. As models are developed for the new processor, library models may be updated with new timing information and the architecture reevaluated.
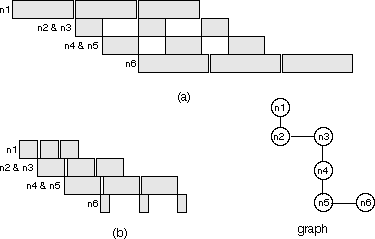
Figure 7 - 8 shows example timelines for the two architectures in Figure 7 - 6 for the 6 - node graph in the figure. The 6 - node graph is a simplified representation in which n1 and n6 represent the graph partitions allocated to hardware in Figure 7 - 6, and n2, n3, n4, and n5 represent the software partitions. Timeline (a) represents the mapping of the six graph nodes to the four processors shown in Arch #1 of Figure 7 - 6 and timeline (b) represents the mapping of the graph to Arch #2, which contains two-special purpose ASICs. The example illustrates a much improved overall timeline for the architecture when n1 and n6 are mapped to custom ASICs, all other processing being the same. The importance of the example is to illustrate that different architectures and graph mappings to those architectures can be evaluated quickly, which is especially valuable in large systems.
At this point of the design, it may become obvious to the design team that a custom processor or special-purpose ASIC is required to meet the program requirements. If custom hardware is required for a viable solution to the requirements, we can define and support what-if elements in the library and assign processing times associated with them for the DFG nodes. We can evaluate the new element; if satisfactory performance is achieved, we can start the appropriate hardware model development in parallel with the architecture selection process. Or, if desired, we can invoke a processor synthesis tool that is driven from the DFG primitives. The synthesis tool outputs VHDL compatible with down stream detailed design tools.
In this iterative process, we can modify the partitioning, mapping, and the architecture as part of the optimization process. Tools support interactive design changes to both the architecture and/or the partitioning and mapping. Of particular interest is the ability for designers to quickly modify the processor interconnect topology for large architectures. The candidate architectures are each evaluated with respect to the established selection criteria, and then we may select one or more architectures for further consideration.
Inputs to the architecture verification process include the selected architecture instantiation, which includes all or a portion of the implementation partitioning/component list, the optimized DFGs, the CFGs, detailed software description, and the hardware/software reuse library. Note that overall functionality has not been verified before this point. The role of architecture verification is to verify functionality and more detailed performance of the candidate implementation using a combination of testbed hardware, simulator(s), and/or emulator(s) before detailed hardware implementation. This is the first real step in hardware/software codesign verification and is important to verify the virtual prototype defined to date. This process can iterate with the architecture selection process to 1) optimize the selected architecture and 2) update model performance in the RASSP library. As shown in Figure 7 - 9, the major steps in this process are autocode generation, performance simulation, reassessment of architecture attributes, new element development, component mix evaluation, definition of a verification approach, simulation development, and performance and functionality verification.
Outputs from architecture verification include new library elements, detailed specifications for hardware development, and performance and functionality verification.
Figure 7 - 10 shows the 6-node graph replaced by a 4 - node equivalent graph in which the nodes are aggregated as dictated by the partitioning and mapping. The performance simulation at this level accounts for communication protocol so that detailed network contention is evaluated. If necessary, we can modify the partitioning, the architecture, and/or the DFG until performance is satisfactory. Modifications, of course, require iterating through the process steps again.
NOTE: It can be argued that these three steps (autocode generation, performance simulation, and refine implementation analysis) could be allocated either to the architecture selection or architecture verification process.
An integrated framework supports mixed-domain simulation so that high-level performance and functional simulation can be coupled with ISA or RTL simulators, hardware emulators or hardware testbeds. The goal of the verification process is to validate operation of all architectural entities and the interfaces between them before detailed design. The specific verifications required depend upon whether the design is all COTS, mixed COTS and new hardware, or all custom hardware.
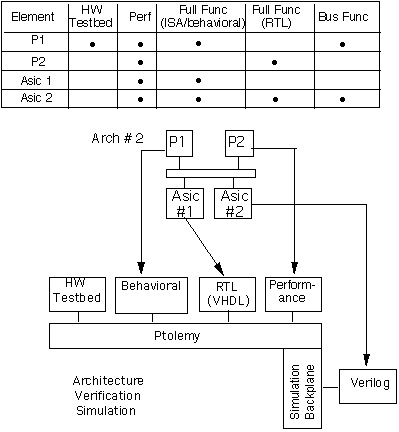
Constructing the hierarchical simulation is based upon the availability of models supporting the entities in the architecture. In some cases, there may be available hardware testbeds for COTS processors, in which case using them is the most effective approach. In general, there may be models available at different levels and in different languages. While it is a goal on RASSP to use VHDL as a common language, we are taking a pragmatic approach to enable use of all available modeling technologies. If sufficient models have not been developed during the design process, we must create them at this point. Based upon model availability, we map the architecture to appropriate simulation engines. Illustrated in Figure 7 - 11 is one of the simulation mappings that could be run; the process envisions a set of hierarchical mappings to efficiently verify the entire hardware/software suite. The interoperability and integration of various commercial tools operating in different domains provides a mechanism to perform efficient simulations for verification. The ideal is to support the interoperability of commercial tools to simulate a complete system in a seamless fashion.
In the event that a hardware testbed is available, detailed evaluation of the performance can be readily obtained through tools that provide detailed timelines of both processing and communication on the architecture. The ability to perform point-and-click mapping of functions to processors provides a way to fine-tune the application, as required. This approach is most useful when performing Model Year upgrades to an existing signal processing system.
We finish this iterative selection process when one or more candidate architectures satisfies the overall requirements. The IPDT reviews the choices and again selects one or more of the candidates for detailed design.
During the system definition process, we develop the initial system requirements. These requirements typically include all external interfaces to the signal processor; throughput and latency constraints; processing flows by operating mode; all mode transitions; and size, weight, power, cost, schedule, etc. We define five items directly related to the subsequent software development:
This architecture design phase of development involves the creating and refining of the DFGs that drive both the architecture design and the software generation for the signal processor. The input to this phase is the executable functional specification for a particular application and the command program specifications. We then partition and allocate the graph(s) to either hardware or software. During the architecture definition process, the DFG(s) of the signal processing is developed and the elements allocated to either hardware or software. We simulate the flow graph(s) from a functional standpoint and a performance standpoint until an acceptable hardware/software partitioning is achieved that meets the signal processing system requirements. This process contains many intermediate steps and graph objects defined in the following paragraphs.
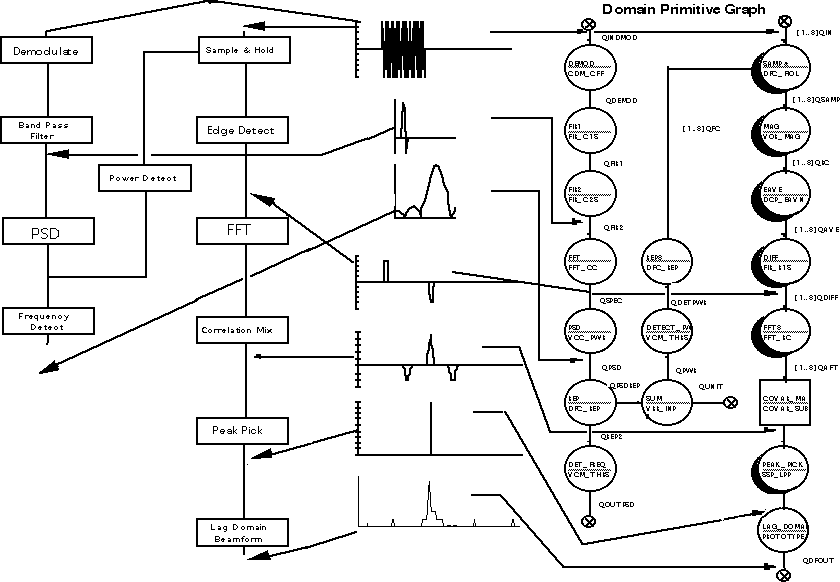
The architecture-independent DFG (domain-primitive graph) is a PGM graph refined to contain only domain-level primitives and subgraphs. The domain-primitive graph created during function design may be refined during the architecture selection process. This graph becomes the functional baseline graph for the application once it has been validated with the test vectors developed for the algorithm flows. The relationship between the algorithm flows and the target-independent DFGs (which are derived in part from the algorithm flows) is shown in Figure 7 - 13.
This figure shows an algorithm flow (shown as a functional block diagram) for a hypothetical application being translated into an architecture-independent DFG (domain-primitive graph). The domain-primitive graph is validated against the algorithm flows produced during system definition. A part of the validation of the domain-primitive graph is the creation of suitable test vectors. The domain-primitive graph is validated once the test vectors produce the same results predicted
from the algorithm flows. These test vectors are later used for graph validation throughout the application development process.
Generating the domain-primitive graph may involve an intermediate step in which the PGM graph is composed of domain primitives, domain subgraphs, prototype primitives, subgraphs, or any entity that can specify the workings of an algorithm. This permits continuation of the architecture selection process concurrently with generation of the domain-primitive graph when new primitives are required.
Figure 7 - 14 shows a candidate architecture and the segments of the domain-primitive graph assigned to either hardware or software components, which will be executed on the candidate architecture.
Figure 7 - 15 shows the creation of the software partitions from the allocated graph. The hardware partitions are omitted for simplicity and are shown as ASICs. In this example, ASICs are assumed to be the final form of the hardware partitions as they apply to the code downloadable to the target processor.
The domain-primitive graph must be re-partitioned for each candidate architecture. The criteria we use in determining the optimal partitioning scheme included the system throughput requirements, latency, memory, etc. We can iterate the partitioning and the architecture to achieve improved performance, cost, reliability etc.
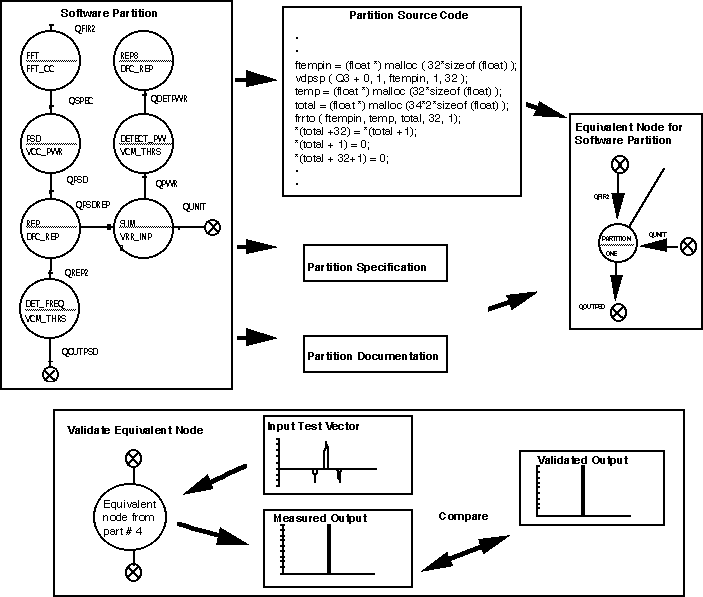
Figure7 - 16 shows the derivation of an equivalent node for software partition #1. The software partition is transformed into a stand-alone partition graph that is represented by source code, a partition specification, and documentation. We use the partition specification and source code to create an equivalent node for the partition, which has the same characteristics as the subgraph represented by the partition. We use the equivalent node to build an equivalent graph in which each node represents one of the original graph s partitions, either hardware or software. The equivalent node is validated using the same test vectors used to test the graph partition. This process is equivalent to the traditional software unit test.
As we partition functionality between hardware and software, we model the hardware components in VHDL at the abstract behavioral-level; the software components are expressed in a pseudo-language, DFG, program design language (PDL), or ADA. We develop architectural performance (network simulation) models in VHDL. The software components exist in files that can be interpreted and executed by the VHDL models for co-simulation/co-verification of the candidate processor implementation.
The output of the architecture design process is a test bench and a model for each component.
We must capture the timing and resource-usage behavior of the candidate architecture s hardware components in abstract/non-evaluated VHDL models. (Non-evaluated means that the actual data operations are not performed; rather, just the time required and the control aspects are modeled. Another term for this type of abstract model is "token-based".) Algorithmic operations that have been partitioned into software are expressed in software descriptions. The control aspects of these software descriptions must be interpretable by the non-evaluated VHDL models of the programmable hardware components.
The architecture model, taken as a whole, consists of the structure interconnection of the components, their abstract VHDL models, and the associated software descriptions. The architecture model forms the executable specification of the architecture design, and the VHDL component models form the executable specifications of the hardware components that are passed on to the hardware design process.
Associated with each VHDL component model is a VHDL test bench. The VHDL test bench is a set of VHDL modules that provide stimulus to the component model and check its response, so that we can verify the behavior of the component to meet its requirements. We design the VHDL test bench for each hardware component before the component model is designed. Since the architecture model is more detailed than the system-level performance model, the more precise results of its execution are back annotated to the system model. Likewise, as we obtain the results from the more detailed hardware models in the hardware design process, they are back annotated to the architecture and system models, which makes them precise.
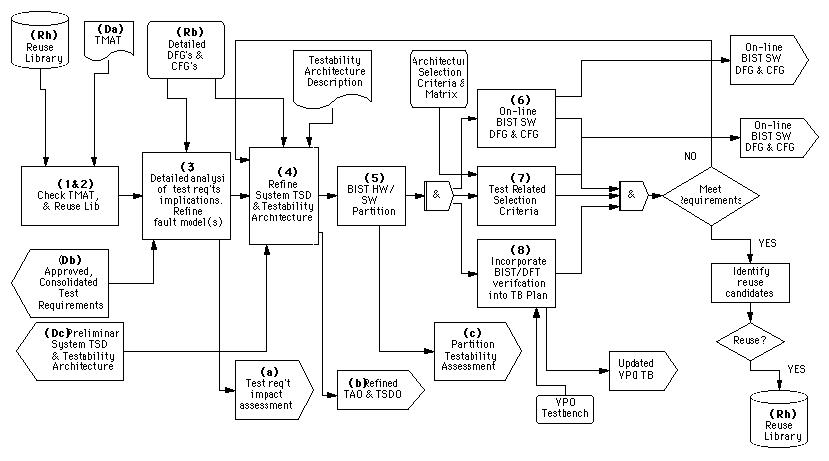
The functional design step provides a more detailed analysis of the processing requirements (including BIST), resulting in initial sizing estimates, detailed data and control flow graphs for all required processing modes to drive the hardware/software codesign, and the criteria for architecture selection. Figure 7 - 17 shows the DFT steps which occur during functional design.
During architecture selection, various candidate architectures are evaluated through iterative performance simulation and optimized to appropriate levels of detail. A trade-off analysis based on the established selection criteria results in the specification of the detailed architecture, and software partitioning and mapping. As part of the trade-off analysis, information is used from the required cross disciplines such as reliability and testability (either manually or through design advisors) to populate the trade-off matrix. Figure 7 - 18 shows the DFT steps which occur during architecture selection.
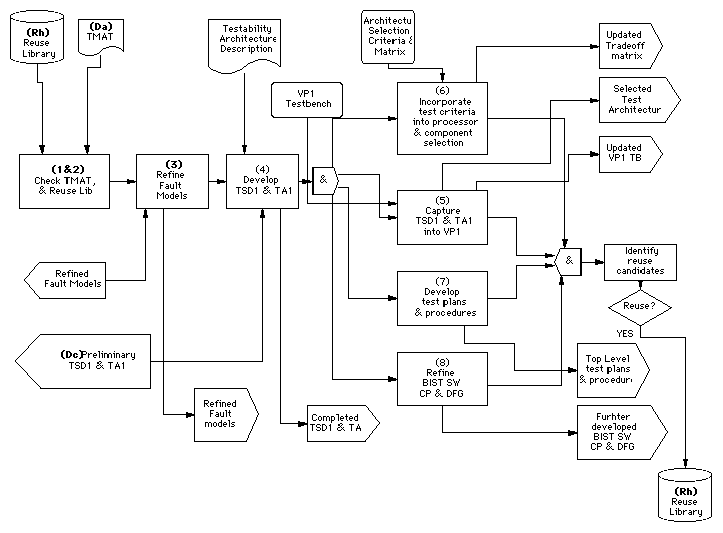
This portion of the process is heavily dependent on the reuse of architectural (hardware and software) components to provide significant time-to-market improvements. In addition, during architecture selection, all software not represented by the DFGs is designed. Based on the requirements, the non-DFG software may include BIST1, downloading data and code, and diagnostics. The virtual prototype, VP1, produced during architecture selection is not a full system prototype, since function and performance are simulated independently and may or may not be coupled with the overall control mechanism. Several architectures may be selected for
verification during the following step (i.e. primary candidate and risk reduction alternatives). The Architecture Selection level test strategy diagram, TSD1, and testability architecture, TA1, are developed concurrently with VP1 for each candidate architecture.
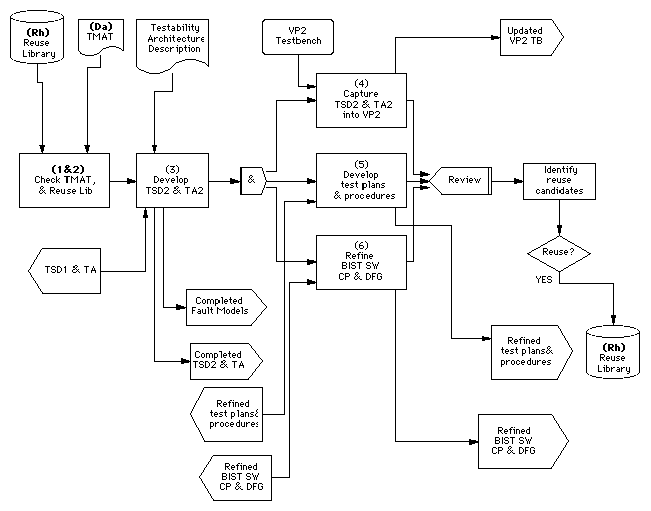
Architecture verification is the process of hierarchically simulating both the functionality and increased performance detail of a selected architecture candidate. Up to this point the overall functionality has not been verified. An integrated, simulation-framework supports mixed-domain simulation so that high-level performance and functional simulation can be coupled with ISA or RTL VHDL simulators, hardware emulators or hardware testbeds. The goal is to validate operation of all architectural entities including embedded test and the interfaces between them before detailed design. Software partitions are autocoded to produce software modules translated from the processor independent library elements to optimized, processor specific implementations. The resultant virtual prototype, VP2, is passed onto detailed design. The Architecture Verification level test strategy diagram, TSD2, and testability architecture, TA2, are developed concurrently with VP2 for the selected and verified architecture. Figure 7 - 19 shows the DFT steps which occur during architecture verification.
During the architecture definition step, the "lead, follow, or get out of the way" strategy for COTS at the testability architecture level is developed. Controllability and observability analysis results are used to determine what solution(s) could be examined for sections anticipated to employ COTS. The possibilities are explored of absorbing some or all COTS functions (that are in non-testable devices) into ASICs or FPGA type devices that incorporate at least boundary-scan, if not BIST. A refinement of the COTS fault model also takes place.
Like the other disciplines, the mechanical engineering representative(s) on the PDT primarily contributes to defining the selection criteria parameters based upon the overall program requirements. Given the complexity of a given architectural design, it may be necessary for mechanical/packaging personnel to provide inputs regarding the desirability of one design over another based upon the amount and/or type of cooling necessary to implement the design within the form factor required. The total power requirement of each candidate architecture may meet the overall power budget allocated during the system design, but the power dissipation per volumetric unit may dictate different approaches for the different architectures. These characteristics may impact the overall packaging approach, accessibility for test, maintainability, and cost; all of these should influence the ultimate architecture selection.
7.0 Architecture Design Process Detailed Description
The architecture definition process for RASSP, shown in Figure 7 - 1, is composed of three steps: functional design, architecture selection, and architecture verification. The process strives to provide a comprehensive hardware/software codesign capability, where
Likewise, hardware functions are verified via simulation before detailed hardware design. An iterative, hierarchical simulation process is used to perform this verification at several levels of complexity.
In either case, the architecture selection process can proceed by postulating hardware or software elements that can be used in the high-level architecture performance simulations (e.g., defining a new element with 2X performance of existing element). Concurrently, we can initiate new activities to start the hardware modeling effort required for the custom hardware or start the development and validation process for a new software library element.
Software Reuse Library
Hardware Reuse Library models
7.1 Functional Design
Initial efforts in architecture design include an implementation analysis of the algorithms to assess the required operations per second and memory and I/O requirements. Processing flows may be optimized based upon implementation experience and knowledge of reuse libraries. The two primary functions in functional design are formalizing the criteria to select an architecture and translating the processing flows to an architecture-independent DFG constructed from reusable library elements. The functional design process is also an opportunity for the signal processing architect(s) to assess the complexity of the required processing. The goal is to take the functional algorithms and translate these into preliminary implementation form. Initially, we size and establish a criteria to select the architecture, as shown in Figure 7 - 2. We translate processing flows for all modes to architecture-independent DFGs constructed from reusable library elements, which may represent either hardware or software. In addition, we translate control requirements into the appropriate control flows.
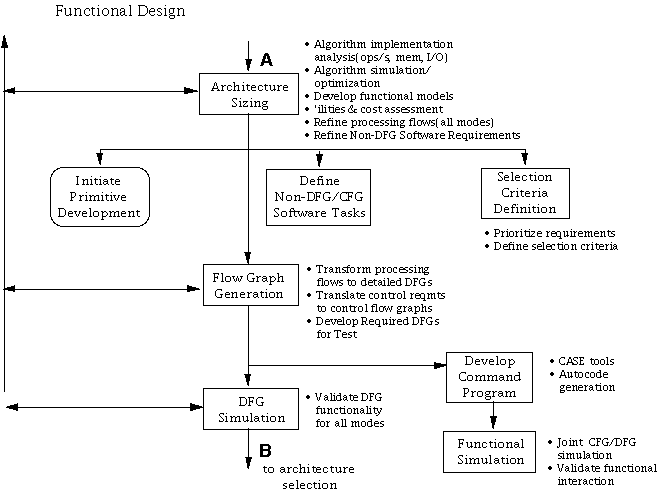
7.1.1 Architecture Sizing
We analyze the system requirements and processing flows for all required modes in terms of estimated operations per second, memory requirements, and I/O bandwidths processing requirements. We can make initial size, weight, power, and cost assessments based upon rules of thumb and experience sizing estimates. We also develop a first-pass partitioning of hardware and software functionality at this point. We develop requirements for non-DFG/CFG software. Functional models may be developed where necessary and algorithm simulations and optimization performed to refine the processing flows and derive the detailed requirements for the signal processing. The resulting functional processing flows represent the detailed algorithms that must be performed for each required mode.
7.1.2 Selection Criteria Definition
We prioritize the overall system requirements and the derived requirements and establish a selection criteria. The selection criteria provides the necessary basis for subsequent architecture trade-off analysis. An example of typical parameters used in processing trade-offs studies is shown in Table 7 - 2.

7.1.3 Define Non-DFG/CFG Software Tasks
We review the non-DFG/CFG software requirements and define the tasks required to fulfill these requirements.
7.1.4 Flow Graph Generation
We transform the finalized algorithm processing flows into the detailed DFGs as the first step in hardware/software codesign. In parallel, we optionally develop any DFGs which are specifically for test. These DFGs are based upon either the Processing Graph Method (PGM) developed by the Navy or the GEDAE™ method and tool developed by Lockheed Martin ATL. PGM is a specification for defining detailed DFGs for signal processing applications. It is supported by older, non-graphical development tools. GEDAE™ is a newer, graphically oriented tool environment that is also integrated with a command program generation tool and a performance modeling tool. Either of these will work within the process however, GEDAE™ has become the tool environment of choice due its ease of use and modern programming environment. The DFGs are made up of the reusable library elements, which may represent either hardware or software. The resulting DFGs represent the composite algorithmic requirements for all processing modes. The algorithms to date have been mostly functional in nature, without regard to specific implementation issues such as processing efficiency. For example, the DFG may include a filter. Resultant efficiency will be related to whether a time-domain or frequency-domain implementation is selected, which may in turn depend upon the processor under consideration. Note that if several architectures are considered, unique sets of architecture-specific implementations may be chosen.
7.1.5 Command Program Development
We transform the state and process models via autocode generation into prototype code that will be used with the DFGs to simulate the interactions among graphs, particularly mode transitions. The command program must be able to accept messages from outside the signal processor, interpret those messages, and generate the appropriate control information to stop graphs, start graphs, initiate I/O, set graph parameters, etc. We can develop the command program either
through standard software development CASE tools or through the tools that provide autocode generation capability from state transition diagram descriptions. See the Autocoding for DSP Control application note for more details regarding the process and tools for developing the command program.
7.1.6 Functional Simulation
As part of the functional design process, we must simulate both the DFGs and the CFGs. We simulate the DFGs to validate that they represent the same processing as the mathematical description of the processing flows developed during the systems process. We also have to validate various aspects of the CFGs, which must interact with the DFGs. This includes passing parameter information between the external world and the graph management software, initiating or terminating I/O devices, starting and stopping DFGs, etc. Individual DFGs have been simulated previously and their functionality is not in question. However, it is desirable to simulate the interaction of the various DFGs, as dictated by the CFGs, to ensure that all interactions are functionally correct. In particular, it is necessary to know that mode transitions occur properly.
7.2 Architecture Selection
Architecture selection is an automation-aided process to rapidly evaluate different architectural designs and instantiations of these designs. For example, an existing architecture may be simulated with new DSPs to quickly evaluate inserting emerging COTS technology. This is the Model Year upgrade concept. An integrated toolset will facilitate rapid performance trade-offs to select and size a scalable architecture based upon the processing requirements. These trade-offs are tightly coupled with the performance of the software on the architecture. Automated multiprocessor partitioning and mapping, coupled with user intervention, provides a rapid optimization capability. The trade-off process supports the IPDT concept by integrating tools for DFT, cost analysis, and high-level design advisors. In addition, the architecture process is coupled through VHDL to the detailed synthesis of chips, boards or processors.
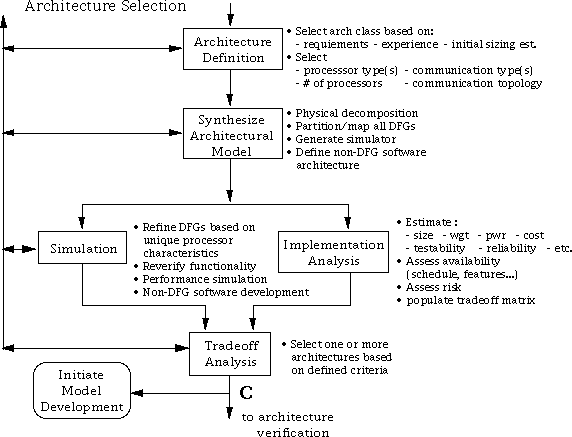
7.2.1 Architecture Definition
The next step in the hardware/software codesign process is specifying an architecture. This includes both selecting a class of architectures (e.g. MIMD, SIMD, etc.) and the design approach within the class (e.g. interconnect topology). This decision is generally based upon a combination of the signal processing architects application domain experience and the system requirements, cost, availability, technology maturity, etc. The architecture should include any processor(s) necessary to satisfy the command program requirements.
7.2.2 Architecture Model Synthesis & Physical Decomposition
The process of defining the architecture is coupled with the allocation of the DFG to the architectural elements. For example, specific nodes in the DFG may be assigned to a custom hardware element such as an FFT chip. To support this capability, the library would contain a hardware model capable of performing the processing defined by the DFG node.
7.2.3 Performance Simulation
Based upon unique characteristics of the individual processors, we can refine algorithms to optimize performance that is verified again via simulation. We also begin high-level language non-DFG software development and simulation. The goal of simulation at this stage is to both verify the algorithms again functionally (if modifications have occurred), and to refine the anticipated performance of the candidate architecture using available throughput, memory, and I/O estimates for these algorithms. We estimate the overall architecture performance via VHDL simulation and analyze it with respect to meeting all signal processing requirements. The performance simulation reflects the established partitioning and mapping of the DFGs. We simulate a particular partitioning and mapping to estimate the overall timeline for the processing. These performance simulations are executed iteratively as we consider different partitioning and mappings in an attempt to optimize the execution timeline. The architecture may be optimized through iteration of architecture synthesis and simulation. After simulation, we can modify the architecture by changing or adding processors, changing communication types, changing interconnect topology or postulating new architectural elements ( what-if analysis) that require subsequent development.
7.2.4 Implementation Analysis
Concurrent with the simulation effort to establish performance, we can proceed with implementation analysis of the architecture, if desired (depending on the degree of satisfaction with the architecture). Any given architecture, or multiple candidate architectures, may be in the process of analysis by various members of the PDT (see Section 7.5.3). For each candidate architecture, we postulate an implementation (using high-level synthesis tools and/or design advisors driven from a VHDL description of the architecture) and transform it into size, weight, power, throughput, and cost parameters, as well as schedule, testability, reliability, availability, and maintainability estimates. This process requires the collaboration of the IPDT to properly assess the attributes of the architecture. In addition, we assess component availability with respect to supporting the desired development schedule. The concurrent use of tools and design advisors speeds the process and leads to better-informed, early decisions. Based upon this analysis, we can assess implementation risk for the different architectures.
7.2.5 Trade-off Analysis
We iterate the architecture synthesis, simulation and detailed analysis process for each candidate architecture to obtain an optimized solution. These activities are directed toward populating an architecture trade-off matrix that is a record of the design process. The trade-off matrix is supported by design notes that document the rationale for the entries in the matrix. We analyze the information gathered from the architecture synthesis process with respect to the selection criteria and weighting established in the functional design process. Based on the selection criteria, we select one or more of the candidate architectures for further evaluation.
7.3 Architecture Verification
Architecture verification is the process of hierarchically simulating both the functionality and performance of a selected architecture candidate. Here, simulations are performed at a greater degree of detail than during architecture selection. An integrated framework supports mixed-domain simulation so that high-level performance and functional simulation can be coupled with ISA or RTL VHDL simulators, hardware emulators or hardware testbeds. The goal of the verification process is to validate operation of all architectural entities and the interfaces between them before detailed design. The specific verifications required depend upon whether the design is all COTS, mixed COTS and new hardware, or all custom hardware. Software partitions are autocoded to produce software modules translated from the processor-independent library elements to optimized processor specific implementations, which are interfaced through a set of standard services built on an operating system microkernel.
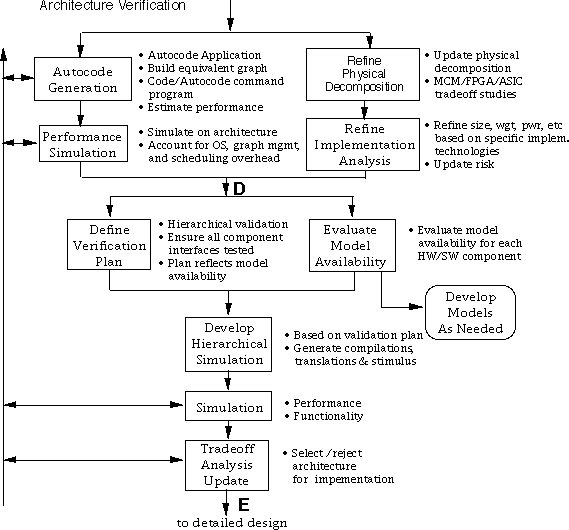
7.3.1 Autocode Generation
The architecture(s) produced in the architecture selection process, the finalized DFGs, and the partitioning/mapping data, provide the necessary input to autocode generation. We use the architecture description and the partitioning and mapping data to automatically generate the software for each of the partitions. We generate the code by translating the processor-independent flow graph primitives to target-specific code which use the optimized math libraries for the specific DSP. The result of this process is definition of a new DFG node (called an equivalent node), which represents the entire graph partition. As part of this procedure, we simulate the resultant code to ensure that the resulting node satisfies the same test bench as the original subgraph. The resulting equivalent nodes from all the graph partitions can be combined into a new equivalent graph that has the same characteristics as the original, but each node represents a software module representing the aggregate processing of a subgraph. We can verify the functionality of this equivalent graph again via functional simulation to maximize confidence in the overall translation process.
7.3.2 Performance Simulation
We generate timing estimates for the autocode-generated software, and performance simulation can be repeated using the new timing estimates. Ideally this simulation is at a greater level of detail than previous simulations. It should account for performance impacts due to the target operating system, the graph management system built on top of the operating system, and any scheduling overhead necessary. The equivalent DFG(s) performance is simulated on the candidate architecture, much like was done in architecture selection, but with a higher degree of fidelity.
7.3.3 Refine Physical Decomposition
We continue to refine the physical decomposition and implementation of the design. We perform MCM/FPGA/ASIC trade-off studies. We update the routability, thermal, and other analyses based on more detailed information.
7.3.4 Refine Implementation Analyses
During architecture selection, we produced the initial estimates for size, weight, power, cost, schedule, testability, maintainability, etc.. We used this information to select one or more candidate architectures for further evaluation. After initial selection of candidates, we can perform a more detailed evaluation of the architecture attributes. This may include reiteration of size, weight, power, and cost estimates based upon particular implementation technologies, such as MCMs, surface-mount technology, etc. This activity involves various disciplines from the development team. The architecture description of viable candidates may again be processed using hardware synthesis tools and various design advisors to produce the updated architecture attributes. We can assess increased costs due to architecture modifications necessary to meet reliability requirements, since these could impact final architecture selection.
7.3.5 Model Availability
Architecture verification is the process of hierarchically simulating both the functionality and performance of a selected architecture. In general, we perform the simulations at more detailed levels than previously done. In preparation for architecture verification, we must determine the level of hardware and/or models available for all architecture components. This becomes the basis for defining a functional verification approach. For each architecture component, the hardware may exist and be available, or various levels of models may exist in the library, including behavioral models, ISA models/simulators, RTL models, and/or performance models. In the ideal case, all software components in the reuse library have performance data for each processor supported in the library. In reality, this performance data is most likely generated on an as-needed basis. Consequently, for each software component not supported by performance data for a required processor, we must evaluate the availability of hardware and/or various level models to support validation of that software component. The availability of these hardware components and/or models provides constraints on the verification plan.
7.3.6 Verification Approach Definition
An architecture verification plan should be developed that ensures, to the maximum extent possible, that all hardware components will function and interoperate as expected and all software will execute properly on the architecture when built. This will likely require a hierarchical approach to the architecture verification. Virtual prototyping the entire architecture at the RTL-level requires an exorbitant amount of time. The plan must, however, ensure that all component interfaces are tested, all devices properly communicate with each other, and all software executes on the appropriate processor.
7.3.7 Simulation Development
The objective of this process is to enable incremental functional and performance evaluation of hardware and simulation models throughout the design process. We do this by providing an integrated suite of tools that support a combination of testbed hardware, simulator(s), and/or emulator(s) to fully verify performance and code functionality before hardware implementation. The ideal approach is to integrate these disparate simulators through a multi-domain backplane that enables mixed-mode simulation. The multi-domain simulation capability should support the following elements:
7.3.8 Simulation
Executing the constructed, multi-domain simulation provides performance and functionality verification. The detailed simulation provides:
7.3.9 Trade-off Analysis Update
The iterative process of simulating the various architectures and the graph mappings to them, along with the PDTs estimation of the architecture attributes, using interactive tools where available, results in the completion of the trade-off matrix shown in Figure 7 - 12. The results of the various trade-off studies are reflected in population of the trade-off matrix, which is a record of the design process performed. The entries in the table should be supported by detailed notes to provide both designers and program management insight into the rationale behind the selections.
7.4 Software in Architecture Definition Process
This section provides a discussion of the software related activities in the architecture process. It is intended to provide a consolidated description of how requirements are translated to software in a DFG driven process.
7.4.1 Domain Primitive
Domain primitives are library elements that describe an element of processing to be done. The primitives are HOL programs that perform the graph interface and processing functions of a graph node. Graphs programmed at the domain-primitive level can be automatically translated into graphs executable on any supported target.
7.4.2 Domain-Primitive Graph
The section uses PGM as the examples to explain the Domain-Primitive Graph. GEDAE™ examples can be found in the Hardware/Software Codesign application note, the Data Flow Graph Design application note, and the GEDAE™ web page.
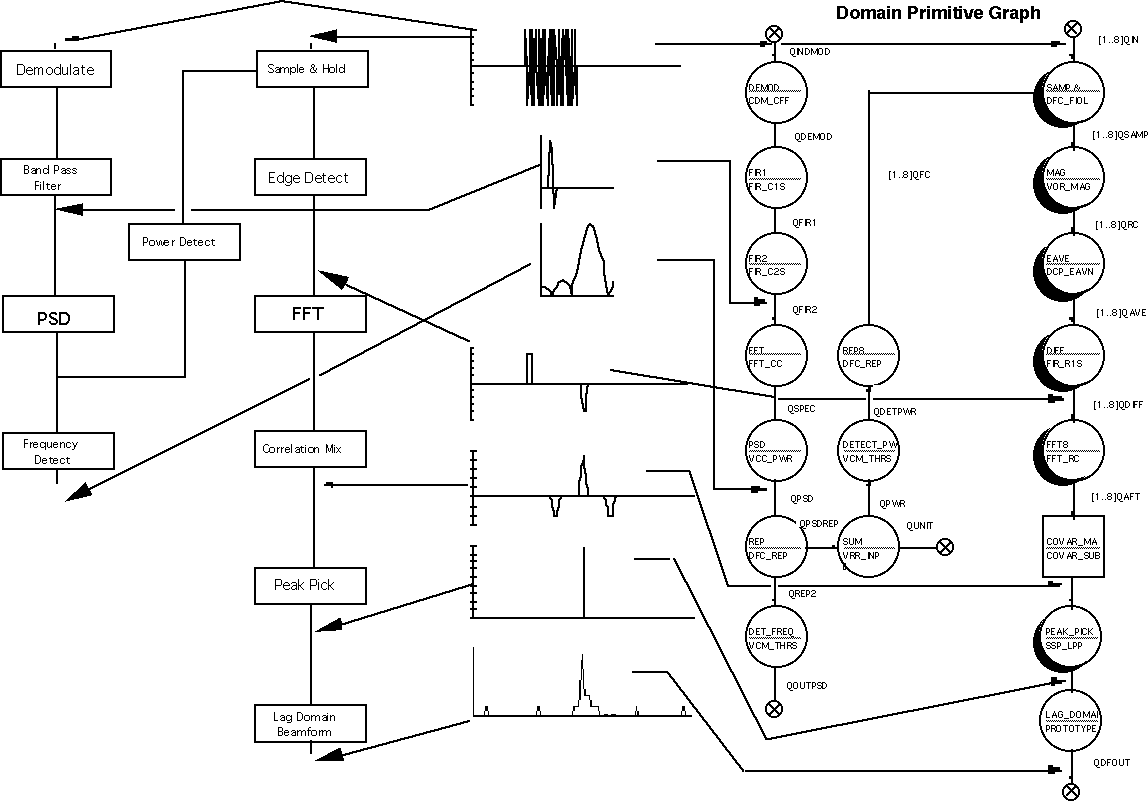
7.4.3 Allocated Graph
We produce the allocated graph by assigning each domain-primitive node or subgraph of the domain-primitive graph to hardware or software. Each node or subgraph must either be allocated to a hardware component contained within the candidate architecture or be identified as a software component to be run upon a processor class contained within the candidate architecture.
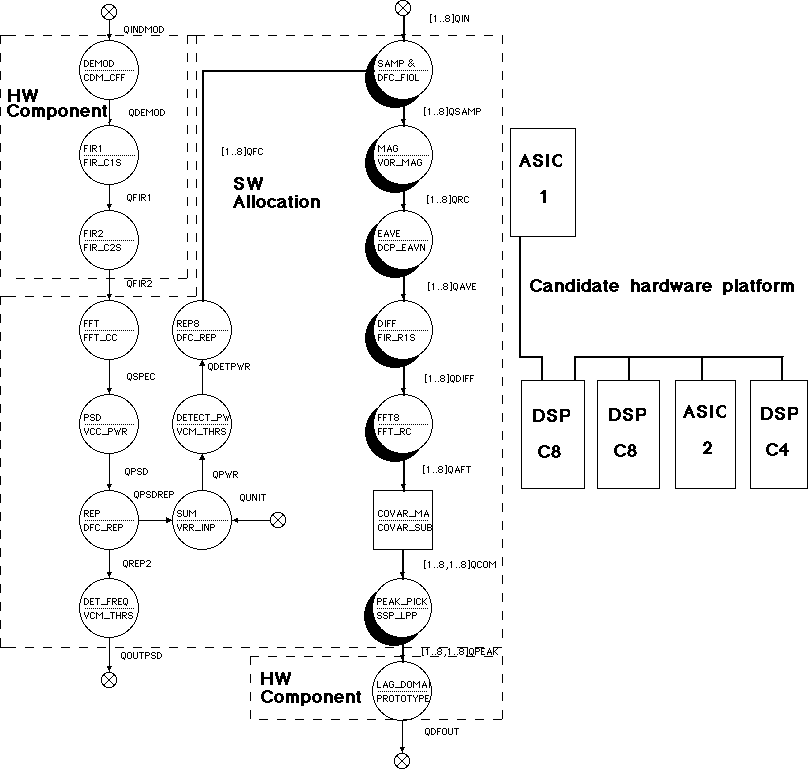
7.4.4 Partitioned Software Graph
The partitioned software graph is the software portion of the allocated graph. It has been partitioned into units of software that will be mapped to individual processors in the architecture. It represents all domain-primitive nodes and subgraphs allocated to software partitions. It is important in its own right because it may be partitioned separately from the full graph to optimize software partition performance.
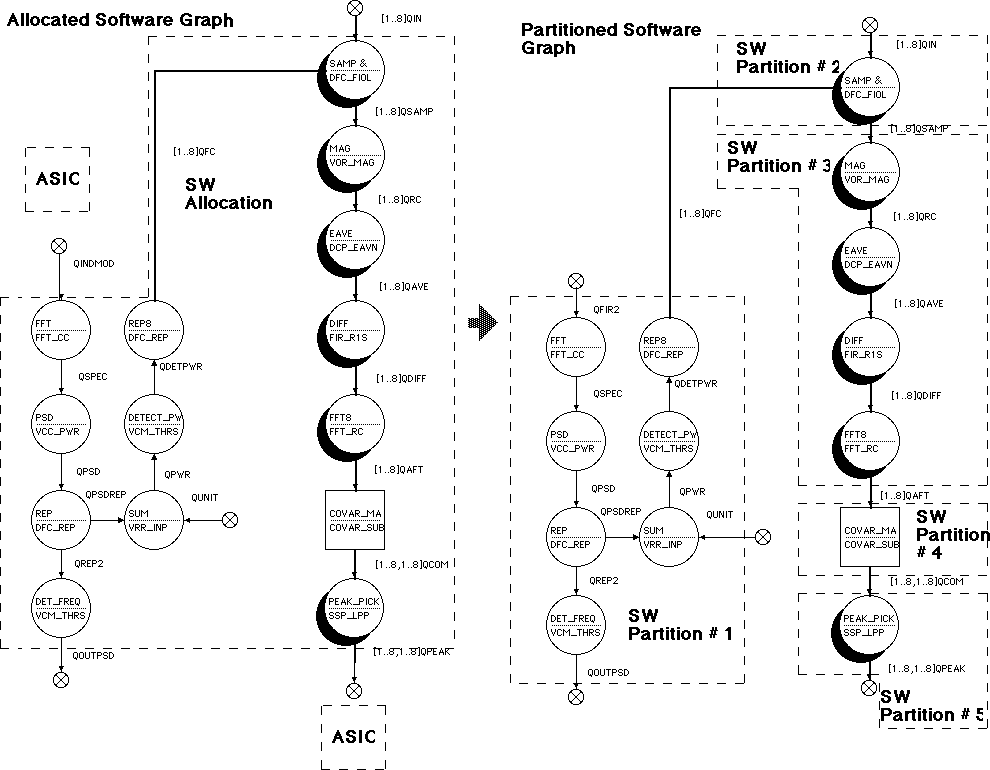
7.4.5 Partition Graph
A partition graph is a stand-alone PGM graph that represents either a hardware or a software partition in the original domain-primitive graph. We build partition graphs in the autocode process, and use them to construct equivalent nodes for each partition. We also build simulation interfaces for each partition to simulate the application.
7.4.6 Equivalent Application Graph
We produce the equivalent application graph from the partitioned software graph by replacing each partition with its equivalent node. The equivalent graph is a PGM graph in which all partitions identified in the partitioned graph are replaced with equivalent nodes. The equivalent graph is executed using the same test vectors used during the domain-primitive graph simulations, and it is considered functionally validated if the output vectors of the simulation match the output vectors obtained from the domain primitive graph simulations.
7.4.7 Command Program
In parallel with the graph allocation, partitioning, and performance simulation on a candidate architecture (which is aimed at concurrently optimizing the architecture and the software partitioning), we develop a command program that controls the behavior of the graphs. The command program can interpret the messages received from the external source (operator or higher-level command and control system) and execute the detailed graph commands that control operation of the signal processing graphs within the signal processor. See the Autocoding for DSP Control application note for more details.
7.4.8 DFG/Command Program Functional Simulation
At any point along the development path, we can interface the command program with the DFGs representing the signal processing and these can be jointly simulated to ensure that the graphs are correctly managed within the overall context of the application. Of particular interest is the ability to properly execute mode transitions, which may require stopping, starting, and initializing different graphs; starting and stopping I/O; setting graph variables; or passing data and/or parameters to the external world. This joint simulation ensures that all modes operate properly and transitions between modes occur as required by the specifications.
7.4.9 Non-DFG Software
Non-DFG software requirements tasks and architectures are defined during the architecture process. We develop all code to the maximum extent possible.
7.5 Other Considerations in the Architecture Design Phase
7.5.1 Use of VHDL in Architecture Process
At this point in the process, we have specified DSP system network topology and partitioned the DSP system functionality onto architectural (the hardware/software) elements. We model functionality in terms of timing, resource usage, and algorithmic operations. VHDL is used to model subsystem timing and resource usage. Additional details on performance modeling and its use within the design process can be found in the following application notes:
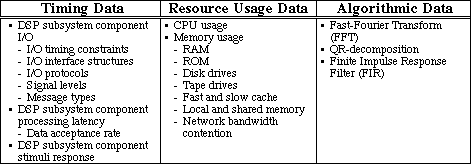
7.5.2 Design For Test Tasks in Architecture Definition
Architecture Design is comprised of three sub-process steps: functional design, architecture selection and architecture verification. The primary focus of the DFT activities is to develop a test strategy and architecture consistent with the requirements captured during system design. DFT interacts with the functional process to affect architecture decisions and component selection. A virtual prototype of the test & maintenance architecture is developed and used to perform Hardware/Software codesign with the test software. Additional details on how to do design-for-test can be found in the Design-for-Test application note.
7.5.3 Role of PDT in Architecture Process
The architecture process is not only an ideal candidate for concurrent engineering, it is defined in such a way that concurrent engineering is mandatory. By definition, the process includes elements of systems, hardware, and software engineering, and it is supported heavily by the other disciplines, as reflected in the integration of hardware estimates, costing, mechanical complexity, thermal issues, software support, and RAM-ILS parameters into the architecture selection criteria. The following paragraphs describe the role of the PDT disciplines in the architecture process.
7.5.4 Design Reviews in Architecture Process
The architecture design team leads preparations for this review and prepare the design package. At ADR, we present all architecture trade-off studies performed and the selection criteria developed. We present and review the final recommendation of an architecture to be carried forward. The results of all preliminary performance and behavioral simulations that support the recommendation are included in the design package. We present all architecture verification simulations and any additional architecture selection trade-offs we conducted as a result of the verification process. We present detailed results from the verification steps to ensure that the architecture design meets all specifications before release to detailed design. We establish the influence of all disciplines contributing to the architecture selection and define all external interfaces to/from the signal processing system.
The architecture design team supports preparations for this review and supports the preparation of the design package.
The architecture design team supports this review based upon the participation in the integration and test activities and any product refinements that occurred since DDR.
![]()
![]()
![]()
![]()
Next: 8 Detailed Design Process Detailed Description
Up: Appnotes Index
Previous:6 System Design Process Detailed Description