Next: 7 Primative Construction Up: Appnotes Index Previous:5 Memory Management
![]()
![]()
![]()
![]()
Next: 7 Primative Construction
Up: Appnotes Index
Previous:5 Memory Management
The threshold either in terms of the stream or vector grouping of the data is used to control the packet behavior of the DF graph. We now examine the situation when a node produces a variable amount of data. If we desire to maintain a consistent firing order of the downstream nodes we can either dynamically change the threshold to correspond to the data amount produced by upstream node or we can have this node produce a V array. In the case of the V array, the threshold can be kept constant to one V array and now the node will always produce one V array every time it is fired. The sequence of node firings is maintained for any amount of data produced by each of the individual nodes using the V arrays. The data stream of a V array contains count items. The first item is the actual amount of data produced and the second item is the maximum amount of data that could be produced followed by the number of data items. The V array is useful for building embeddable graphs that requires the firing order to be determined at compile time of the embeddable code. The V array keeps the node execution sequence of the graph static and fixed at compile time, while allowing for internal dynamic data length variability.
An useful extension to the queue structure would be a queue that contains a structure. Even though the current DF implementations do not support this data structure directly this would be a worth while improvement. The structure definition would contain a mixture of floats, ints and doubles. The structure can be considered as a generalized vector and allow structures in the"C"sense to be passed between processing nodes. An additional extension to the DF graph would be the ability to pass a block of structured memory such as a heap with a pointer to one of the data items in the heap. This queue type would be useful for moving an entire linked list between processing nodes without flattening the list at the output of the send node and then restoring the flattened list to a heap structure format on the receive node. This form of queue would not require the graph to include the additional operations and processing time needed to flatten the list to a stream and then restoring the list into list processing format. The decrease in processing time would come at the expense of increasing the memory size needed to store the entire heap area rather than just the data items that are used in the list.
One method of accomplishing this is to develop a set of new() or malloc() programs which perform the dynamic cell allocation from the heap. However, in this case, the designated block of memory is input to the specialized malloc() so that the cells of the list are from the buffer area rather than the heap. The output queue of the node will now have to support a new data type which will be the entire buffer area and a pointer to the beginning of the list. If the ClustFeat X nodes are separate processors, each node will get a copy of this buffer area and the pointer. The merging of these data sets of this new created type will now have to be defined. When we want to merge many of these buffer areas, we usually wish to combine cells from each one of the lists contained in the input buffers so that a new list can be formed. The input queues would be the n buffer areas and the merge node would combine the lists and put out an updated buffer area with cells of data from the input cells in the form of a new list. This then would be a full support for list processing that would obey the DF paradigm.
6.0 Queue Data Structures
In a DF environment the queues are used to store the data items locally and when the processing is distributed, this data must be sent from one node to another in order to continue the processing. The data types stored on each queue are usually of one type in "C" notation i.e. int, float, double, etc. These data items can be single words or arrays (one to n dimensional). Both the queue of stat and the array are stored contiguously in memory. When arrays are stored, the association is a logical grouping. In this sense, the logical grouping of the queue affects the way the node inputs data. The physical data is always a stream of data and the node following the queue can be set to threshold on n data items in this stream. If we logically organize the data into vectors, the threshold must be set to the number of vectors. The stream threshold would be n while the vector threshold would be 1. Another logical grouping is the matrix. For a matrix of size 'n x m' the threshold for the matrix is 1 and for the stream the threshold must be set to 'n * m' data elements where 'n' is the row and 'm' is the column count respectively.
6.1 Using V Arrays
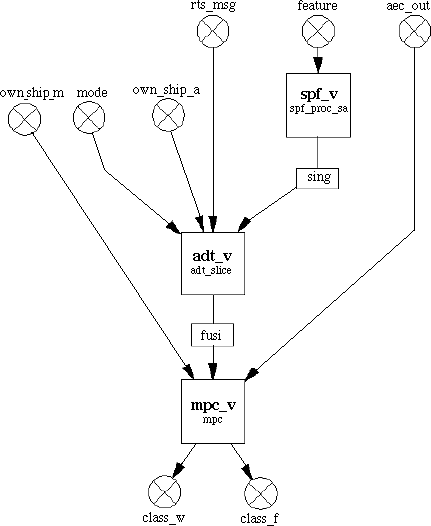
Often the DF mechanism is used to implement a set of data processing algorithms. These processes are very often needed to complete the processing of data sets that have been created by conventional signal processing algorithms. For example in the ETC example, the data set have been produced by a series of beam forming and filtering operations. After these operation, the data set that results is processed by clustering and tracking algorithms. In the ETC example shown in Figure 6-1 is the so called back end processing operated upon cluster data. The three nodes represented by the spf_v, adt_v and mpc_v nodes sequentially process the feature queue. The contents of the feature queue is 0 .. n sets of data of vectors of length seg_size. The feature queue is formed for each slice of processing and the number of clusters contained in this array is data dependent. There is a limit on the number of clusters that may exit per slice. The V array was used as the queue element. In this case, as the node spf_v fires it consumes one V array and produces one V array marking the end of the slice processing. Using V arrays we can also send an empty packet which results when there are no clusters in this slice of data. In order to complete the back end processing, a queue needs to be formed for every slice processed. If a marker was not present when there were no clusters for this particular slice, a synchronization problem would develop for the downstream processes. The adt_v node has three other queues in addition to the main cluster V array and the data in the queues must all pertain to the same slice. By the use of the empty V array, the place marker, the adt_v processing is kept in sync even when the slice contains zero clusters.
6.2 Structures
Very often, the data items in the queue are not all of one type, i.e. integers of floats, but are grouped by a"C"code typedef of structure which allows the mixing of data types. In early DF implementations a work around was used where the structure was passed as a binary array and the data reinterpreted by the receiving and sending nodes sharing the same header with the typedef of the structure. The complications introduced by this approach is that every time the binary queues had to be viewed, programs that read the binary queues and interpreted the results according to the typedef were used. In other cases the mixed types were separated into int and float arrays but from a programming documentation point of view this is a logically disruptive process. In the future DF implementations this structure definition should be implemented.
6.3 Dynamic Structures and Lists
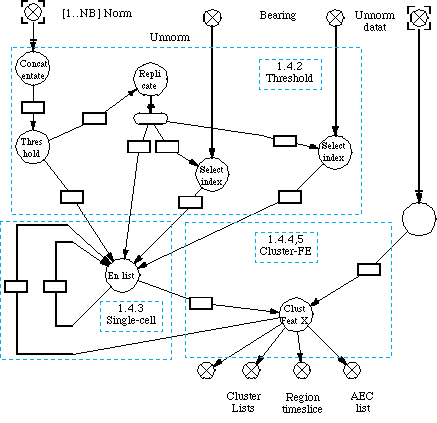
On occasion, the structure used to process data is a linked list. The first node takes a stream of data and creates a linked list of cells that were dynamically allocated from the heap. Figure 6-2, Cluster Feature Extractor (CFE) Graph, shows that the En list node creates a linked list and when the list is completed the clustering algorithm is run in the node ClustFeat X. In this DF graph when the node En list executed, only a token was passed to Clust Feat X so this node could begin clustering. The actual data structure remained in the heap and the clustering began at the beginning of the list as indicated by the list pointer. Since there was only one copy of the heap the two nodes En list and ClustFeat X, have to be on the same processor. DF processing is not supposed to work this way. If the processing performed by Clust Feat X had to be performed in parallel then there would have to be copies of the list sent to each one of the clul processes.
![]()
![]()
![]()
![]()
Next: 7 Primative Construction
Up: Appnotes Index
Previous:5 Memory Management