1.0 HDI Functional Analysis and Preliminary Architecture Assessment
To satisfy the overall requirement of a 100 X throughput density improvement, a goal of 45 processor elements was established for the HDI function. At the beginning of the first cycle, the critical design issues were:
- Identification of implementation and optimization approaches.
- Establishing the number and type of processors/boards needed.
- Definition of the software architecture approaches.
A variety of implementation approaches were possible. Each presented distinctly different implications based on:
- the size of the total processing task
- the partitioning granularity
- the characteristic nature of its inherent data flow.
In addition, certain approaches were inconsistent with the numerical precision needed to meet the SAIP requirements.
The potential hardware implementation approaches included a variety of COTS products with significantly different architectures. The software architecture approaches included a wide range of partitioning strategies, levels of granularity, and control schemes.
The software issues were intimately related to the hardware issues. At the outset, the complexity of the HDI application established that a programmable solution offers flexibility and is more practical than a hardwired implementation.
The initial candidates for programmable processor elements were the Intel i860, the Motorola PowerPC, and the Analog Devices Sharc processors. The i860 and PowerPC were both capable of efficiently performing IEEE 64-bit double-precision arithmetic, while the Sharc was limited to IEEE 32-bit single-precision arithmetic. The E-Spec was based on double-precision arithmetic, which indicated a potential requirement for double-precision which would have eliminated the Sharc candidate.
Candidate COTS board products differed in the distribution of memory and the DSP interconnect network. Mercury Computers Inc. provided a high bandwidth RACEway interconnection network. Ixthos and Alex Computer Systems rely upon VME-bus and Sharc-link connections. All options represented significant hardware/software trade-offs in functionality, processing density, power, and cost. The goal was to determine the best match of the application's requirements.
To select the best implementation solution, the critical development areas were prioritized based on their inherent dependencies. The architecture decisions depended upon the algorithm requirements, and all detailed design factors depended in-turn on the architecture. As a result, the critical design issues and the related risk retirement activities were prioritized as follows:
- Algorithm implementation tradeoff and optimizations
- Architecture evaluation and selection, and
- detailed HW/SW implementation and integration
Final
Plan To Address Issues
The first phase plan was established to investigate the algorithm and determine the critical implementation issues. The following risk retirement activities were initiated:
- Analyze the HDI algorithm to determine:
- Precision - minimum required, 32-bits or 64-bits.
- Memory - minimum required, organization, allowable distribution.
- Computations - number, type, rate.
- Data Flow - transfer requirements, distributions, partitioning granularity
Tools
The tools used for automating and assisting the HDI analysis process were:
- ANALYZE - to extract the calling tree and define data flow of legacy code, and
- GPROF - to measures compute-time of the individual code sections.
Algorithm Analysis
The HDI algorithm processes a low resolution image region to produce a higher resolution image by extracting fine detail from the original image's phase information. The process involves more than a simple linear interpolation of image intensity values. The HDI algorithm belongs to a class of super-resolution algorithms. Figure 1 - 1 shows an example of the HDI process.

Figure 1 - 1 : HDI Algorithm Image Chip Processing Example The HDI algorithm consists of many sub-algorithms as pictured in the following flow-graph.
The HDI algorithm was provided by MIT Lincoln Laboratory in the form of documentation and an Executable Specification (E-Spec). The documentation helped in understanding the algorithm, but lacked the detail needed to specify correct implementation of such a complex algorithm.
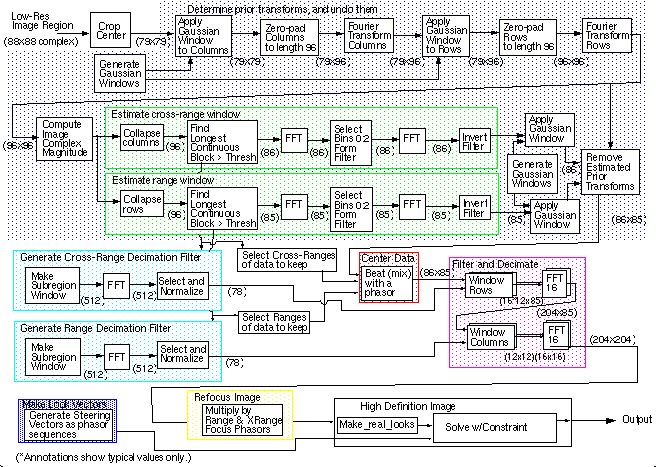
Figure 1 - 2 HDI Algorithm Flow-Graph Combined with the documentation, the E-Spec was invaluable for rapid understanding and test of alternative implementations. It was unambiguous, testable, and detailed. The E-Spec was a reference to generate intermediate and final test data. This data was used to accelerate the development by forming a test-bench early in the project. The E-Spec also helped by providing a starting-point for implementation.
The E-Spec consisted of a large combination of program files in three languages and a large number of Source Lines of Code (SLOC). Initially we had difficulty executing the E-Spec. The problem was aggravated by the combination of languages which made up the E-Spec. Programs containing multiple interacting languages tend to be sensitive to the precise configuration of the host software environment. This decreased the program's portability.
The problems caused by integrating languages negatively impacted the automated analysis tools we had planned to exploit. The inability to execute the E-Spec prevented automatic profiling during the initial phase when it was most needed. The presence of the C++ and Fortran languages prevented use of our automatic C-code analyzer tool. An important lesson learned from this project is that there are many advantages to using a common language throughout a project.
Portions of the E-Spec code had been translated from the original Mathworks Matlab code and were highly convoluted. These portions contained a lot of indirection and multiple copies of data variables that referenced the same data using different variable names. The code was deeply nested in subroutines that were spread across many files. These characteristics made the E-Spec difficult to follow and hindered analysis and understanding.
MIT-LL later provided a Matlab description of the HDI algorithm. The Matlab version both helped and hindered. It introduced a fourth language variant of the algorithm that differed from the E-Spec. Mismatches were detected between the Matlab and E-Spec; subroutines, variable names, and logic and arithmetic expressions. Being unfamiliar with the application and the code, we found difficulty in judging the significance of the differences. The Matlab version was useful in understanding the overall flow, but heavier reliance was placed on the E-Spec.
The E-Spec was typical of algorithm development code that is provided to embedded system implementors. It was written without runtime or memory efficiency in mind. While difficult to work with, the E-Spec and Matlab code did provide a detailed description of the HDI functional requirements as well as a test bench for alternative implementations. Overall, the availability of an E-Spec is preferable to an ambiguous written specification or design document for describing the required functional performance.
Because of the difficulty in following the original E-Spec dataflows, the code was rewritten to facilitate automatic analysis and conversion to a data flow graph. The rewritten code comprised about 1,600 SLOC, broken down as shown in Table 1 - 1, compared to the 18,600 SLOC in the original E-Spec. It should be noted that the E-Spec code made use of a general purpose function library which accounted for 85 percent of the original SLOC.
The rewrite significantly simplified the code and reduced it's memory requirements. It brought the code into a single language (C), and it reduced the number of files (see figure 1 - 3). The latter was particularly helpful in that it allowed automatic tracing of the data-flow and was more robust for porting to target architectures.
Language Files SLOC C++ 2 316 C 27 2,516 Fortran 10 15,803 Total 39 18,635 Language Files SLOC C 3 1,648 Table 1 - 1 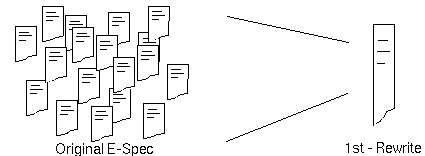
Figure 1 - 3 Rewrite consolidated E-Spec into fewer files The rewritten version provided easy switching between double and single precision. The compile-time precision switch was added to support determination of the algorithm's precision requirements. To verify alternative implementations against the reference E-Spec, a test bench was constructed for the HDI algorithm. The test bench used the low-resolution image chip test data and the output images and target classification results were compared to the E-Spec results.
To facilitate debugging, instrumentation code was inserted into the E-Spec and the alternative version to compare intermediate data between each algorithm step. An automatic comparison utility quickly identified the differences and traced them back to the exact code sections. This supported continuous automatic testing. Visualization displays of the intermediate data were very helpful in isolating errors. The following figure shows an example of intermediate data from the algorithm.

Figure 1 - 4 - Example of Intermediate Data from HDI Algorithm The E-Spec rewrite was time-consuming. There was a strong inclination to skip it in the interest of saving time. However, in the long run, consolidating and simplifying the code ended-up saving much more time than it consumed. The porting and optimization would have required 3-4 times more effort without it. It would also have been very unlikely the subsequent algorithm optimizations could have been obtained.
In retrospect, the rewrite greatly facilitated the analysis and optimization process and as a result is on of the key lessons-learned during BM4.
In summary, the E-Spec rewrite:
• Simplified the original E-Spec code and reduced the memory requirements.
• Converted the code into single language (C), and reduced number of source code files.
• Allowed automatic tracing of algorithm data-flow.
• Provided accurate execution time profiling of the individual HDI functions.
• Facilitated analysis and optimization.
• Provided a robust starting point for porting the final algorithm to the candidate COTS architectures.
Initial Algorithm Analysis Results
Preliminary analysis indicated the need and potential for significantly reducing the operation count of the algorithm, which could be achieved through optimizations that increased its efficiency without changing the overall mathematical functionality. The HDI algorithm required 85 million intrinsic operations per image chip. At 30 image chips per second, the required operation rate was 2.6 GFLOPS/second. Based on this throughput requirement, an initial estimate was developed based on using the original implementation on i860 DSP processors. The table below shows the number of PEs required to achieve this operation rate for 10%, 20% and 40% processor efficiencies. The estimates showed that unrealistic programming efficiencies would be required to reach the 45 PE design goal. Based on these estimates there was a high degree of risk for reaching the goal of 45 processor elements (PEs) to perform the HDI processing.
Efficiency*
Total PEs
Risk/Meets Rqmts
10%
200
Medium/Fails
20%
100
High/Fails
40%
50
Very High/Marginal
* Efficiency = Exhibited Intrinsic Op Rate/Maximum Rated Op Rate Table 1 - 2 Estimate of Required PEs for Original E-Spec Implementation A rough profile of the original E-Spec running on a Sun workstation indicated a large portion of the execution time was associated with the SVD Solve-Image code. The figure below shows the breakdown of CPU time that was initially measured. The E-Spec consumed a total of 93.84 seconds to process one image chip using a Sun Sparc-10 workstation with 64-MB RAM. The initial profiles were imprecise because of difficulties encountered using the E-Spec. Later, the ATL rewrite provided more precise profiles.
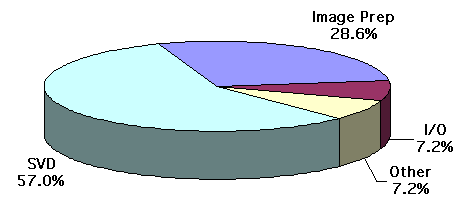
Figure 1 - 5 Original E-Spec Profile Figure 1 - 5 shows a large portion of computations were in the SVD portion of the HDI algorithm. Other pseudo-inverse methods are known to be significantly more computationally efficient than SVD, as shown in Table 1 - 3 below.
(From Golub & VanLoan, 1990, p248)Algorithm
Computational Order
Numerical Robustness
SVD
O(13n3
)Excellent
Modified Gram-Schmidt
O(2n3
)Excellent
House Holder
O(4/3n3
)Excellent
Gaussian Elimination
O(2/3n3
)Poor
Table 1 - 3 Comparison of Alternative SVD Implementations Additionally, the workstation measurements indicated the E-Spec version was using more than 3-MB of memory. This was a concern since one of the candidate DSP processors, the Sharc, offers highly optimal performance if the application can be loaded in its 0.5-MB on-chip memory. In addition, partitioning the HDI application at a sub-image, fine-grain level to distribute it across multiple processor elements would introduce additional communications and synchronizing overhead. As a result, reducing the HDI algorithm memory requirements became a high priority design issue.
In addition to uncovering the benefits of replacing the SVD function, analysis of the rewritten E-Spec identified other potential areas for major reductions in the number computations and memory usage. Based on these discoveries a projection of a 3x computational savings was developed. Using these projections the estimate for the number of HDI processors required was updated to reflect the projected computation estimates. The projected size/risk implications of the algorithmic were implemented are shown in Table 1 - 4.
Efficiency*
Total PEs
Risk/Meets Rqmts
10%
68
Medium/Fails
15%
45
Moderate/Satisfies
20%
34
High/Exceeds
* Efficiency = Exhibited Intrinsic Op Rate/Maximum Rated Op Rate Table 1 - 4 Projected PE Requirements Based of Optimization Estimates Conclusion of Preliminary HDI Analysis:
The outcome of the analysis during the first spiral cycle indicated computational efficiency improvements of the algorithm were essential to attaining the SAIP design goal. It also showed improvements were possible through a few high payoff algorithm optimizations.
The original plan had assumed that only minor algorithmic optimization would be necessary or possible. It assumed detailed coding efforts would begin quickly after only a brief algorithm analysis phase. Based on the outcome of the initial HDI development effort, it was clear that an expanded effort to optimize the computation implementation offered the potential for not only significant long term savings but that the savings for the prototype system would offset the NRE for the optimization efforts.
In a notable departure from traditional methodologies, the RASSP design process recognized information from its phase-1 activities and responded to the fact that a lower risk approach was to apply more effort to a few crucial algorithm optimizations. The algorithmic optimizations, in combination with a straight-forward moderate-risk detailed coding effort, would greatly reduce the total effort that would otherwise be needed to meet the requirements from an extended detailed design phase alone.
The conclusion of the first phase effort was to proceed with the identified algorithm optimization.
2.0 HDI Optimizations / Final Implementation Tradeoffs
At the start of the Architecture Hardware/Software Codesign spiral cycle, the remaining critical issues were identified and prioritized. Six major issues were identified in this phase:
- Reduction of algorithm runtime and memory needed to achieve the BM 4 design goals.
- Determination of the required precision sensitivity to meet the functional requirements
- Selection of the appropriate DSP processor element (PE) and COTS boards
- Determination of the number of HDI boards
- Initiation of GEDAE™ data flow graph (DFG) capture and primitive development
- Estimation of GEDAE™ runtime and memory overhead
These issues were interrelated and not easily separable. The algorithm runtime and memory reductions, as well as the need for double precision arithmetic, were important for determining the overall size of the system. A requirement for double precision arithmetic would eliminate all Sharc candidates. These issues were critical for selecting the final COTS processing boards and for establishing the number of boards needed. The purchase order for the boards was a "long-lead" item that was estimated at 60-days to delivery. The algorithm optimization was also crucial to the capture and refinement of the HDI DFG.
Plan to Address Issues:
A systematic plan was established to address these issues. The specific risk retirement efforts were:
- Establishing BM4 algorithm system testbench
- Construction of a HDI processor virtual prototype
- Optimizing the highest throughput HDI functions
- Identifying and benchmarking critical algorithm threads on candidate DSP processors
- Capturing GEDAE™ DFG and developing the necessary DFG primitives
- Determining GEDAE™ overhead, benchmark critical sections in GEDAE™.
- Trading-off and selecting COTs boards for the HDI processing
To test and verify algorithmic optimizations and implementations, an automatic testbench was needed. The testbench used the available test data to check alternative algorithm implementation results versus the E-Spec results. The test data set consisted of 70 image chips. Because the role of the system is an automatic classifier, algorithmic modifications such as precision sensitivity had to be validated against the E-Spec classification scores.
An algorithm-level virtual prototype was also needed to test implementation alternatives and measure optimization runtime and memory improvements. The algorithm virtual prototype described the algorithm but did not describe any architectural details. The virtual prototype was tested in the testbench. Timing profiles of the algorithm virtual prototype were used to guide the optimization effort and select the critical code sections for benchmarking on the candidate processors. To determine the extent of overhead added by GEDAE™ several critical threads of the HDI algorithm were captured in GEDAE™ and benchmarked on the candidate processors. This timing information was used to select and order the processing boards.
Tools:
The following tools were used to accomplish the HDI hardware/software codesign tasks:
- GPROF - to measure the runtime breakdown and guide optimization
- HDI Testbench and Virtual Prototype - to evaluate and verify functional and relative runtime and memory requirements for alternative algorithm implementations
- ImgConv, XV, XGRAPH, - to enhance testbench data visualization and control
- GEDAE™ - to capture and test HDI DFGs and primitives
Progress
The completed single-language rewrite of HDI E-Spec was verified in the testbench for equivalence against the original E-Spec. It enabled a precision sensitivity study, accurate profiles, and efficient algorithm optimization. The sensitivity study indicated single precision arithmetic would not appreciably degrade the end-to-end classification performance or the image quality. This result enabled further consideration of the Sharc as a candidate processor element. The algorithm rewrite served as the basis for the algorithm virtual prototype and all further implementation optimizations.
Once the HighClass testbench and virtual prototype were established, a visual control panel was developed to control the testing process. The visual control panel included status indicators and image visualization as shown in figure 2 - 1. The testbench provided a complete, comparative analysis of HDI, LRC, and HRC for alternative implementations against the E-Spec results. It also provided automatic testing on the complete set of test images. The automatic evaluator included comparison of output to the reference images, classification rankings, and scores. The system-level testbench was invaluable for validating correct implementation and rapid optimization.
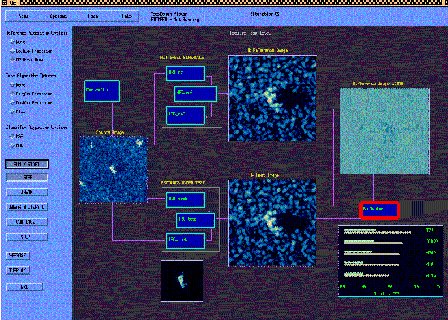
Figure 2 - 1 System Visual Virtual Prototype and Testbench Initially, processing the 70-image test-set required more than an hour. Therefore, incremental optimizations during the day were tested quickly using a small subset of the test data. This returned results within minutes, allowing several iterations per day. At the end of each day, a regression test on the full test set was run over night.
Algorithm Optimization Results:
The optimization process was approached by identifying and attacking the dominant computational functions. Usually this represented a small section of code, such as a few loops or lines of code, which were easily optimized. Optimizations involved modifying access methods for more efficient cache utilization, or substituting faster sub-algorithms. Examples of the latter would be: substituting FFT for DFT, applying Horner's rule to matrices, or replacing a time-domain convolution filter with its FFT based frequency domain equivalent.
After optimizing a section, the total computation time was reduced, and the optimized section no longer dominated the execution time. The process was then iterated by identifying the next most dominant section. In general, this process need only be iterated a few times because the majority of computations usually reside in a small number of routines. For example, 5% of signal processing code may represent 95% of the total computation time. The majority of code normally does not need to be optimized.
Profile measurements shown in Figure 2 - 3 of the HDI algorithm indicated a large matrix multiply (Decomp) accounted for 66% of the total computations. We discovered the multiplicand matrix contained several symmetries that could be exploited by factoring the large multiplication into several smaller multiplications with partial sums. This matrix factoring approach was numerically equivalent, and did not modify the processing results. This optimization had a dramatic effect on the execution run time. It reduced the DECOMP operation, which accounted for 2/3 of the total computations, by more than 7 to 1.
After implementing the DECOMP improvement, the Singular Value Decomposition (SVD) accounted for 44% of the remaining computations. As noted during system design phase, other pseudo-inverse techniques were known to be roughly 6x more efficient than SVD. SVD produces some unique information that is especially useful for design analysis. However, the HDI algorithm was using SVD to apply a matrix factorization equivalent for pseudo-inverse. We replaced SVD, and some of the associated code, with a numerically equivalent Modified Gramm-Schmidt (MGS) routine. As in the previous optimization, the overall algorithm performance was unchanged. The testbench showed the HDI with the substituted MGS subroutine produced the same numerical results as the SVD subroutine. The replacement of SVD by the MGS factoring routine reduced what had been 44% of the computations by a factor of 5.7 to 1.
Additionally, the MGS routine is significantly simpler and its data access approach can be vectorized more effectively than SVD. This accounted for further improvements on the candidate DSPs. The following figure shows the history of our optimization effort in terms of the run time reductions during the project as well as a break-down of the computational changes as the most significant sections were optimized.
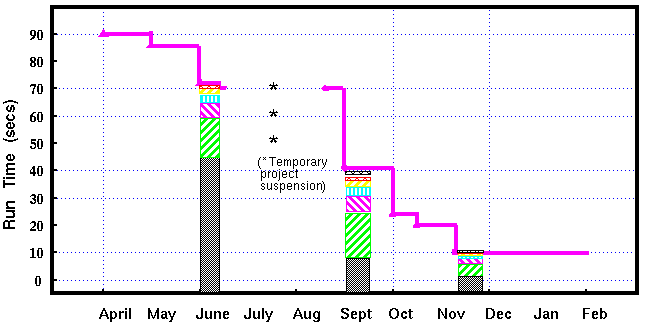
Figure 2 - 2 HDI Run Time on Sparc - 10 for One Image Region Versus Project Date 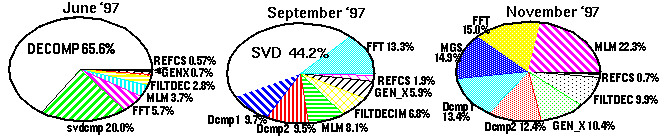
Figure 2 - 3 Distribution of Computations at Three Points in the Optimization Process (From Sparc-10 profiles) In addition to the profile information, algorithm operation-counts were used to understand the relative sizes of the constituent computing tasks. The table below shows the distribution of operations from the original algorithm and after the final optimizations. The extent of optimization for each routine is shown, as well as the impact to the total op-count.
HDI Operation Counts in MFLOPS
Original Algorithm
ATL Optimized Version
Ratio
Decomp
45.7
Decomp
6.3
7.3:1
SVD
23.5
MGS
4.1
5.7:1
Invert
1
Backsolve
0.3
MLM
7.7
MLM
11.4
0.7:1
FFT
5.8
FFT
3.0
1.9:1
Decimate
0.8
Decimate
0.5
1.6:1
Miscellaneous
7.1
Miscellaneous
2.5
2.8:1
Total
85.0
Total
26.2
3.3:1
Table 2 - 1 Optimization efforts continued until the op-counts showed that a coding efficiency of less than 15% was required to meet the project goals. This was deemed to be a reasonably achievable efficiency for highly optimized code on the candidate COTS DSPs.
The required coding efficiency was calculated for the budgeted 45 processor elements at a processing rate of 30 images per second. This implies that there are 1.5 seconds of processor element CPU-time available per image. Programming efficiency is calculated as the intrinsic operation rate divided by the peak-rated operation rate of the processor element.
(26.2e6 Ops/1.5 Sec) / (120e6 Rated Ops/Sec) = 14.6% Efficiency
The Sharc can perform one multiply and two-adds each clock cycle at a clock rate of 40-MHz. Therefore the Sharc possesses a peak rating of 120-MFLOPS/Sec. This peak rating can only be sustained for specialized operations. Because of this, as well as the fact that additional cycles must be used for loading/storing, and computing indices, the actual achieved operation rate is usually much lower than the peak rating.
One early concern was that the use of GEDAE™ might add significant overhead to the processing efficiency. To get an understanding of the amount of overhead added by GEDAE™ a core thread of the critical HDI routines was captured and benchmarked. This test indicated that GEDAE™ added a very little overhead (less than 1%). Similar investigations into memory usage indicated less than 40-KB of overhead.
The algorithm optimizations also reduced the data memory requirements from 3-MB to 200-KB. This was significant because it proved the application could be efficiently contained in the Sharc's 512-KB on-chip memory. Without this reduction, COTS DSP board architectures with no external memory, would have been at a severe disadvantage for the SAIP application.
Processor Tradeoffs:
The DSP board tradeoffs were based on the estimated compute densities and costs. Compute density is the ratio of the amount of computations that can be performed to the volume occupied. Due to form-factor constraints, we considered only 6U-VME boards. Volume depended directly on the number of boards required. The number of boards depended on the number of DSPs needed and on the number of processors on a vendor's board.
The candidate processor boards were those for which the GEDAE™ software environment was ported. These consisted of the programmable Commercial-Off-The-Shelf (COTS) processor boards from:
- Mercury Computers,
- Ixthos, and
- Alex Computer Systems.
Candidate processor elements included:
- Intel i860,
- Motorola PowerPC, and
- Analog Devices ADSP-21060 (Sharc).
The number of processor elements required to perform the HDI algorithm at 30 image chips/second was determined using:
- documented run times
- benchmarks of vector library routines for critical HDI loops,
- iteration counts provided by the virtual prototype and the profiler.
Our optimized HDI implementation was characterized by extensive numerical algebra operations. These included complex and real vector multiplies, adds, and dot-products. Approximately 15% of the computations involved FFTs. A considerable number of the operations were integer for indexing, and the balance were floating-point calculations.
Processor comparisons indicated the i860 and Sharc processor elements would perform the application at roughly the same rate. However, available vendor products provided more Sharcs per board than i860s (18-Sharcs vs. 12-i860s). This gave the Sharc boards a distinctive advantage in compute density. The comparison further indicated the PowerPC would perform the HDI application at roughly twice the rate of the Sharc. However, the vendors offered three times as many Sharcs per board than PowerPCs (18-Sharcs/board vs. 4-PowerPCs/board). Again this gave the advantage to the Sharc COTS candidates.
The Mercury board products offer a high-speed RACEway interconnection network, while other vendors rely on VME and/or Sharc-links. Performance simulations were conducted to evaluate the interconnection requirements. These performance simulations indicated the HDI/Classifier communication requirements could be met by Sharc-link. Therefore, vendor specific interconnect features were not required.
Ultimately, the tradeoffs were reduced to a comparison between the required number of a vendor's boards and their cost, as shown in table 2 - 2. The trade-off matrix indicated the Alex Sharc boards offered both the minimum volume and minimum cost solution by clear margins.
Processing Board Trade-off Matrix
PE
Estimated HDI Runtime (Secs)
Number of PEs Req'd
Number of PEs / Board
Number of Boards / Cost
i860
1.6
48
12
4 (med)
Sharc
1.5
45
18
2.5 (low)
PowerPC
0.8
24
4
4 (med)
Table 2 - 2 Comparison of Candidate COTS DSP Boards The benchmarks, profiles, and vector-library based runtime estimates indicated the HDI throughput could be met with approximately 45 Sharcs, or about 2.5 Alex Sharc boards with moderate risk. Similar results from the MSE Classifier analysis indicated a need for approximately 28 Sharcs, or about 1.5 boards. As a result, four Alex boards were selected for the final system implementation.
Detailed Code Optimization:
When the Alex Sharc boards were delivered and installed, detailed code optimization began. First the optimized HDI code was compiled for the Sharc processor. Similar to the algorithmic optimization process, profile information was used to guide the optimization process. After identifying the dominant routine, the C-code was replaced with an equivalent hand coded assembly level function. The following table shows the run-time profiles of the compiled HDI C-code for the Sharc compared with the optimized assembly code version.
Single Sharc HDI Runtime Profiles
Routine
C-Code
Optimized Code
Speed-up
GNorm
4.79
.035
13.7x
MGS
2.1
0.15
14.1x
Decomp1
1.89
0.25
7.6x
Decomp2
1.66
0.24
6.9x
MLM
0.84
0.17
4.9x
MRFFT
1.13
0.13
8.6x
Pre-CompIndex
0.43
0.05
8.6x
Filter & Decimate
0.71
0.15
4.7x
Radx-2 FFT
0.49
0.05
9.8x
Make Look
0.38
0.04
9.5x
Backsolve
0.19
0.02
10.5x
Subtotal
14.63
1.60
9.1x
(Not optimized)
(Projected Times)
Collapse
0.05
(0.02)
Refocus
0.04
(0.01)
GenDecimate
0.03
(0.01)
Other
0.07
(0.07)
Subtotal
0.19
(0.11)
Total
14.83
(1.72)
Table 2 - 3 An average speed-up of about 9 to 1 was obtained from the detailed code optimization. This is typical of the roughly factor of ten that we have experienced with other Sharc applications. The final run time obtained (1.42 seconds) was less than the original estimate of 1.5 seconds. Further optimizations were identified, particularly for the MRFFT function, that yielded run times lower than the original estimate.
Conclusion:
The RASSP top-down design approach resulted in optimization gains at two levels. Algorithmic optimizations yielded a 3.3:1 reduction in the number of operations required to perform the HDI function. Then detailed software optimizations yielded another 9:1 gain using a high speed embedded DSP. These optimizations had a 30x multiplicative impacts on both the cost and volume of the final design.
The application of interacting hardware/software codesign techniques supported the selection of the Alex Sharc board which provided further multiplicative gains of 2.3 in cost and 1.5 in volume over the original Mercury Sharc boards. Software issues helped drive the hardware selection at the same time hardware issues were influencing the software optimizations. These special optimizations enabled the use of vendor boards requiring 33% fewer boards and costing 66% less than more sophisticated boards having external memory and/or custom high speed interconnect networks.
The RASSP design processes resulted in multiplicative reductions of 70:1 in cost and 45:1 in volume. In contrast, a traditional bottom-up methods would have benefited only from the detailed code optimization. This would have achieved a 9:1 or perhaps 10:1 improvement in both cost and volume. The design process would probably have taken as long, or longer, considering it would not have benefited from the code simplifications. More code would have needed to be optimized and would have had greater complexity. The per unit cost of the systems would have been (3.3 x 1.5 x 1.5) = 7.3 times greater.
- 3.3 more boards would have been required without algorithm optimizations,
- 1.5 more boards due to less dense vendor product,
- 1.5 more cost per board.
Using $20,000 per board and 2.5 boards per system, the accumulative acquisition cost savings for 100 production systems provided by the RASSP process would be approximately;
7.3 x (2.5 boards x $20,000) - 1.0 x (2.5 boards x $20,000) x 100 = $31 Million
The results of the HDI Architecture Hardware/Software Codesign optimization / implementation tradeoffs activities were significant. They demonstrated that the RASSP emphasis on hardware/software codesign and concept of continuing hardware and software tradeoffs during the architecture design cycle can result in significant size, weight, power, and cost saving in the final system design.
Approved for Public Release; Distribution Unlimited Bill Ealy