The focus of the System Design Cycle was to establish the functional requirements for each of the processing subsystems. MSE Classifier precision analyses were performed during this phase to determine the precision needed in both the templates data and in the computation precision of the classifier scores. In addition, algorithmic refinements were identified that reduced the overall computational requirements.
1.1 Classifier Functional Description
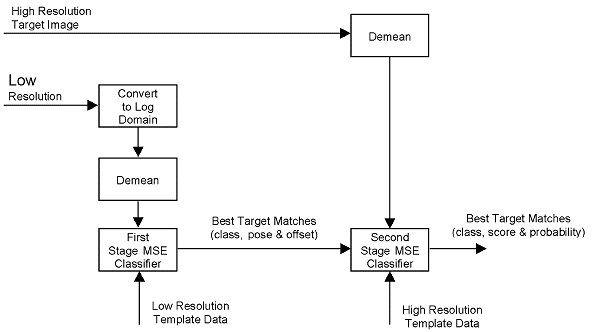
The function of the classifier is to determine which sets of targets in the template library best match the input radar image chip. The top-level block diagram of the classifier is shown in Figure 1-1. The classifier implementation used a two-stage process. In the first stage of the classifier, a score was calculated for each low resolution template file which measured how well the template file matches the low resolution image chip. This score was calculated as
score(m,n) = (1/N) S S ( X(i,j) - T(m + i , n + j) ) 2 i j
where the parameters within this equation are given by
X(i,j) is the input image,
T(m + i , n + j) is the template data,
i and j span the two dimensions of the image data, and
m and n account for different starting offset locations within the template file.
There were 72 pose angles for each target class within the template files. Since the exact target orientation was unknown, various offset (dither) locations are used within each template file to determine the best score for that file. The pose angle and offset location resulting in the best (lowest) score for each target class were determined. The best five target classes were passed to the second stage of the algorithm, along with their respective best pose angle and offset location.
In the second stage of the classifier, scores were calculated for a set of high resolution templates files using the high resolution target image provided by the high definition imaging (HDI) subsystem. The score was calculated in the same fashion as the score in the first stage. The major difference in the second stage was that all template files were used during the first stage to determine the best match, while only a subset of templates were pose angles and offset locations used in the second stage. The subset of high resolution templates used for the second stage were based on the best low resolution target classes and their respective pose angles and offset locations. The second stage classifier returns the best target classes with their classification scores to the SAIP system.
The number of operations required to calculate the scores for each stage of the classifier are summarized in Table 1-1. These requirements were based on the statistics of the template files for the 10 target types provided by MIT-LL in the initial executable specification. A processing rate of 2.9 Gops per second was required to process image chips at an input rate of 30 images per second.
Table 1-1: Classifier Processing Requirements for a Single Image Chip
|
Classifier Stage |
Number of Valid Pixels per Template |
Number of Offset Positions |
Number of Target Classes |
Number of Pose Angles |
Number of Operations (MOp) |
|
First Stage |
|
|
|
|
|
|
Second Stage |
|
|
|
|
|
1.2 Template Precision Analysis
It was originally planned to implement the classifier on a custom board using an FPGA as the basic processing element. This implementation was chosen because the classifier algorithm performs the same three mathematical operations repetitively in evaluating the template sets. Initial classifier analyses were established to determine the number of bits needed to store the template data to reduce the memory requirements for the templates. The templates files, received as part of the executable specification, were in double precision, floating point format. A simulation was developed to model the classification algorithm with various template data precision levels. The simulation was used to determine the number of bits needed in the template data to maintain the accuracy of the classifier. The mean square error of the classifier scores for the test images using the executable specification and the scores using various number of bits of precision for the template data is shown in Figure 1-2 for both stages of the classifier. The full 32 bit, floating point precision was used for both the input image data and the classification computation in this simulation. From these results, it seemed reasonable that at least 10 bit precision was needed to represent the first stage template files, while 8 bit or more was required for the second stage.
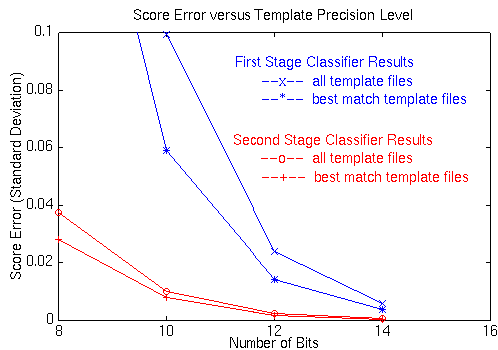
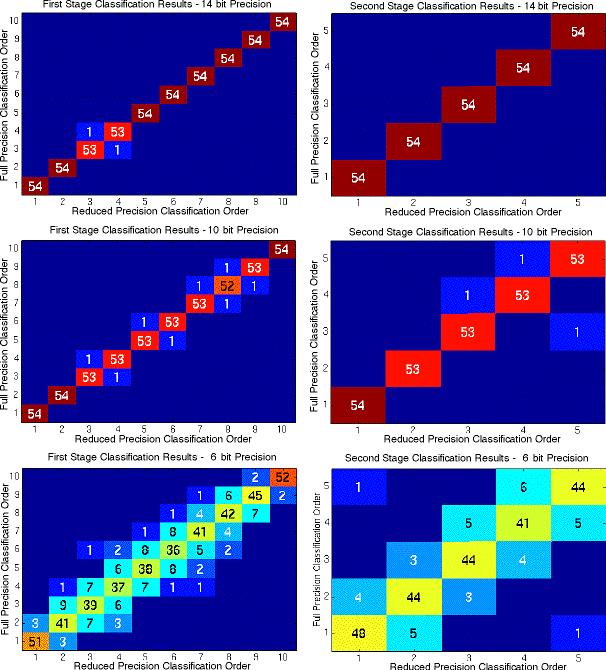
Since there was not a specific requirement for the allowable classification score error, we needed to know how this error impacted system performance. A confusion diagram illustrating the classification rank order differences between the ideal and limited precision templates is shown in Figure1-3 for both the first and second stages of the classifier. In the diagrams, the horizontal axis represents the rank order for the limited precision classifier, while the vertical axis represents the position rank of the ideal classifier. The number within a box represents the number of images (out of the 54 test images) that the limited precision classifier ranked in the x coordinate rank that the ideal classifier ranked in the y coordinate rank. The confusion diagram for a limited precision classifier with no misclassifications would have all of its outputs on the diagonal. These results indicated that acceptable system performance is obtained if 10 bits or more were used for the first stage templates, and if 8 bits or more were used for the second stage templates. Based on these results, classifier memory requirements could be reduced by 50 to 75 percent if the templates were stored using limited precision instead of the full 32 bit, floating point format.
1.3 Classifier Computational Precision Analysis
The initial implementation approach for the classifier was based upon a custom FPGA board. The precision required to compute the classification calculation, with sufficient accuracy, and minimize the number of gates in the FPGA design also needed to be determined. The simulation used to model the template precision was used again to determine the number of bits needed to perform the MSE computation. Figure 1-4 shows the mean square error of the classifier scores for the 54 test images and the classifier score using various precisions for the image data for both stages of the classifier. The first stage templates were limited to 10 bits of precision and the second stage templates at 8 bits for this analysis. From these results it seemed reasonable that 12 or more bits of precision were needed for the first stage classifier computation, and that 10 or more bits were needed for the second stage calculation.
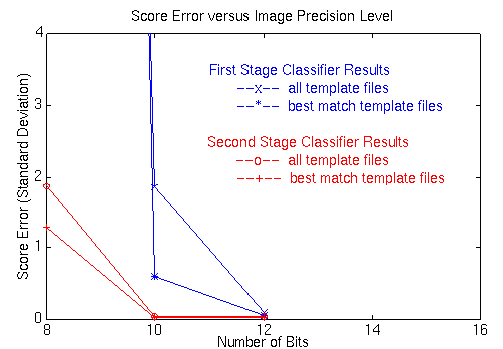
Figure 1-4: Classifier Error Analysis Using Variable Precision for Image Data
Again, we needed to know how this error would impact system performance. A confusion diagram illustrating the classification rank ordering differences between the ideal and limited image precision is shown in Figure 1-5 for both the first and second stages of the classifier. These results indicated acceptable system performance was obtained if 12 bits or more were used for the first stage, and 10 bits or more were used for the second stage.
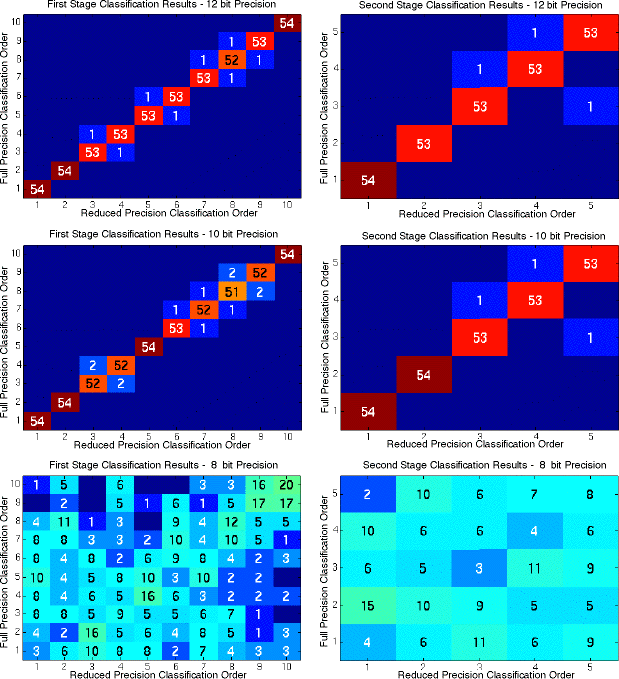
Figure 1-5:Classification Results with Variable Image Precision
1.4 Classification Algorithm Tradeoffs
The classifier is a mean square error (MSE) algorithm since the average of the squared difference between the image and template values is calculated in determining the score. The initial classifier implementation approach was based on a custom board using an FPGA as the computational unit. The multiplier in the classification algorithm required over 85 % of the FPGA gates to perform the squaring function. As a result, the impact of changing the MSE classification algorithm to a mean absolute difference (MAD) algorithm was investigated. The only change to the original algorithm was that the square operation is replaced by an absolute value operation which required no FPGA gates..
A comparison of the MSE versus MAD classification results for the test images are summarized in the tables below. The number of times the ground truth target appeared in a particular rank order of the classifier output is given in these tables. The ground truth target would always occur in the first rank position for an ideal classifier. These results indicated the performance of the MAD classifier is as good or slightly better than the MSE classifier for the test data set. For the MAD classifier, 41 of the 48 ground truth targets were in the top two positions, as opposed to the 38 targets in the top two positions for the MSE classifier. After reviewing these results and understanding the impact on a custom solution, it was determined that either the MSE or MAD algorithm could be used for the classifier subsystem.
|
Mean Square Error (MSE) Classification Results
Ground Truth Target |
|||||||||||
|
Classification Order |
BMP 2 |
BTR 60 |
BTR 70 |
M110 |
M113 |
M1A |
M2A |
M35 |
M548 |
T72 |
Total |
|
Rank 1 |
5 |
2 |
2 |
2 |
3 |
2 |
4 |
3 |
3 |
6 |
32 |
|
Rank 2 |
2 |
1 |
1 |
1 |
1 |
6 |
|||||
|
Rank 3 |
1 |
1 |
2 |
1 |
5 |
||||||
|
Rank 4 |
1 |
1 |
2 |
||||||||
|
Rank 5 |
1 |
1 |
|||||||||
|
Other |
1 |
1 |
2 |
||||||||
|
Total |
9 |
3 |
3 |
3 |
3 |
3 |
9 |
3 |
3 |
9 |
48 |
|
Mean Absolute Difference (MAD) Classification Results
Ground Truth Target |
|||||||||||
|
Classification Order |
BMP 2 |
BTR 60 |
BTR 70 |
M110 |
M113 |
M1A |
M2A |
M35 |
M548 |
T72 |
Total |
|
Rank 1 |
5 |
2 |
3 |
2 |
3 |
1 |
4 |
3 |
3 |
5 |
31 |
|
Rank 2 |
1 |
1 |
1 |
3 |
4 |
10 |
|||||
|
Rank 3 |
1 |
1 |
1 |
2 |
5 |
||||||
|
Rank 4 |
|||||||||||
|
Rank 5 |
|||||||||||
|
Other |
2 |
2 |
|||||||||
|
Total |
9 |
3 |
3 |
3 |
3 |
3 |
9 |
3 |
3 |
9 |
48 |
Table 1-2: Comparison of MSE and MAD Classification Results
1.5 Early Termination Algorithm Enhancements
The original classification algorithm determines the score for each offset location for every pose angle for each of the 20 target classes. Since only the best score of all possible offset positions and pose angles is needed for each target class, we discovered the score calculation could be terminated within a target class if it exceeded the best previous score for the target class. Note the best score is the lowest score. Modifications were made to the classification simulation to take advantage of early termination, and determine the computation improvement for the 54 test images. The computation savings obtained from early termination are summarized in Table 1-3 for each ground truth target type for both the first and second stage classifier. These results indicated the potential for significant computational savings by incorporating early termination in the classifier algorithm. The overall processing rate of the classifier dropped from 2.9 Gflops per second to 1.3 Gflops per second when the early termination algorithm enhancement was applied. As a side note, this simple algorithm modification has been incorporated in the baseline SAIP system.
Table 1-3: Computation Savings Achieved Using Early Termination