Next: 5 Emerging Interface Standards Overview Up: Appnotes Index Previous: 3 Model Year Functional Architecture Technology
![]()
![]()
![]()
![]()
Next: 5 Emerging Interface Standards Overview
Up: Appnotes Index
Previous: 3 Model Year Functional Architecture Technology
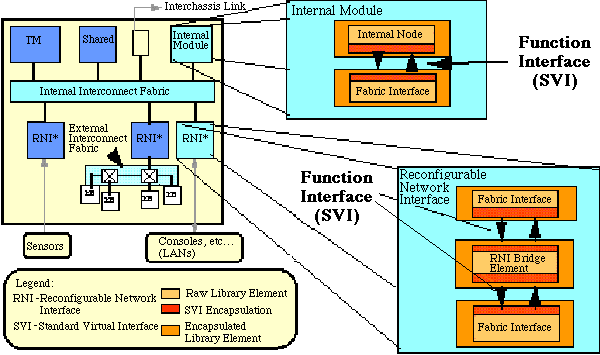
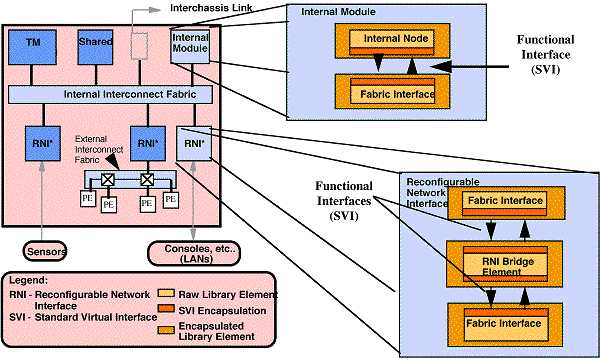
This section describes the levels of interoperability offered within the Model Year Architecture framework, and introduces the concept of encapsulation. Figure 4 - 1 shows the two specific levels of interoperable interfaces that are supported by the model year hardware functional architecture:
Users implement node-level interfaces by encapsulating elements using the SVI. The SVI encapsulation is a VHDL wrapper that ports processor or processor bus interfaces to a common functional interface. The SVI specification was developed as part of the RASSP model-year effort, and interoperability experiments were run by porting several processors to various buses. Discussions of these experiments are included in Section 4.4 with additional details linked in the references.
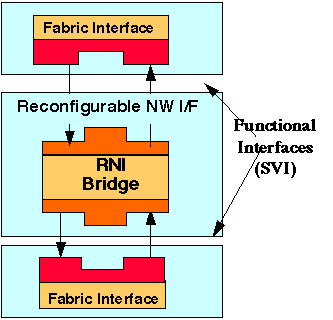
Interconnect-level interoperability is provided using a bridge node between internal and external interconnect fabrics called the Reconfigurable Network Interface node (RNI). An RNI node is constructed from two SVI encapsulations interconnected by a logical layer that ties the two interfaces together. These nodes are usually implemented using a dual-port memory or FIFO and programmable processor or embedded controller. The SVI and RNI are described in more detail in the following two subsections.
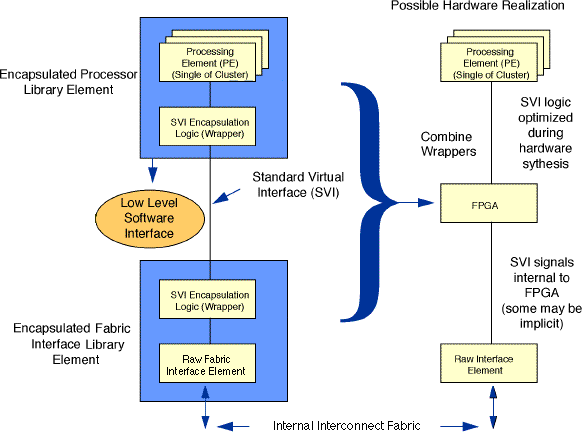
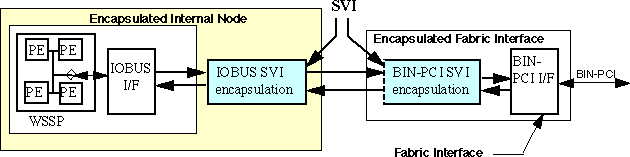
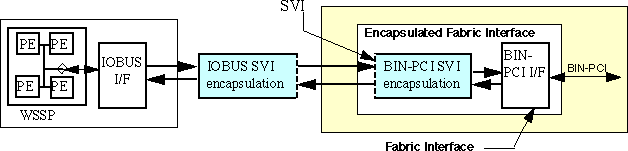
Figure 4 - 2 illustrates how the SVI is used to encapsulate elements of the functional architecture. An internal node can be a single processing element or cluster of elements connected as a single node to a processor bus. Examples of internal nodes include signal processors, vector processors, or shared memory. An interconnect fabric can be any type of interconnect. Examples of interconnect fabrics include XBAR-based, point-to-point interconnect networks, rings, and multidrop buses. Examples of networks include Ethernet, FDDI, Fiber Channel, 1553B, etc.
Each library element (node or fabric interface) includes a VHDL wrapper that implements the SVI encapsulation logic. During the hardware implementation, the logic described within the encapsulations from both sides of the SVI is combined and optimized using synthesis tools to the greatest extent possible, This process may cause some of the signals defined for the SVI to become implicit in the remaining logic. What remains of the SVI is embedded within an ASIC, gate array, or FPGA, and would not appear as explicit pins on a chip or interface connector.
The SVI definition is designed to be general enough to handle different interprocessor communication paradigms. Some interconnect networks support a message passing paradigm to interprocessor communication, while others support a global shared memory paradigm. In some cases there is synchronous operation between the internal node and the interconnect fabric, while in other cases the internal node and the interconnect fabric operate asynchronously. The SVI is by definition synchronous; that is, each word of SVI data is transferred synchronously with the SVI clock. Support for asynchronous operation between an internal node and the fabric interface must be handled by the SVI encapsulation logic.
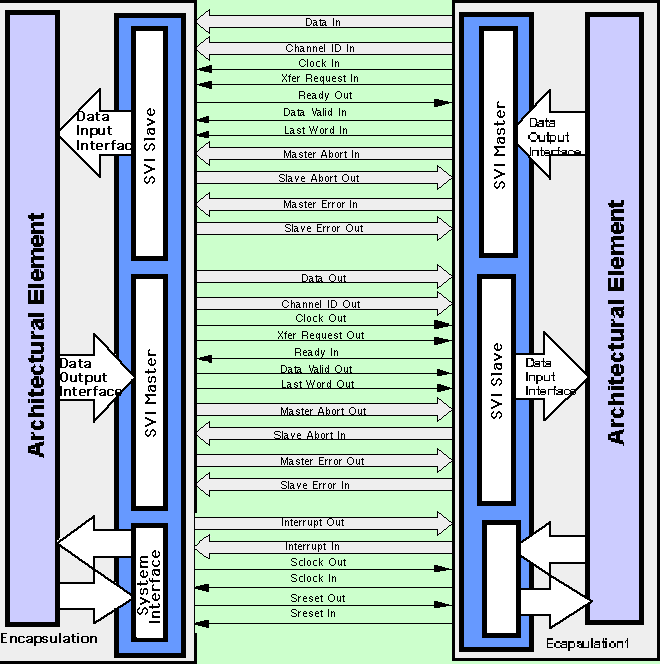
As shown in Figure 4 - 3, the data interface is partitioned into two unidirectional data interfaces: the Data Input Interface which receives incoming SVI messages, and the Data Output Interface which transmits outgoing SVI messages. The data interfaces are implemented with a master/slave pair: the SVI master is a data source to the SVI Data Output Interface, while the SVI slave is a data sink to the Data Input Interface. The encapsulation of a typical architectural element therefore contains an SVI master/slave pair. The advantage of partitioning the data path in this way is that it supports interface architectures with independent, concurrent data passing in both directions across the SVI. A bi-directional data interface can be obtained by using both unidirectional data interfaces controlled by the SVI master and the SVI slave.
A set of SVI commands have been defined to implement the protocol. The SVI command is the first data word transferred across the SVI interface for each message. SVI data paths are implemented in byte increments. This allows encapsulations with different data-path widths. SVI commands occupy the least significant byte of the data bus, and transfer information across the SVI that will be needed by the receiving encapsulation. The address and data, along with any other necessary information, are in the data stream following the SVI command. The SVI master encodes the data in the SVI message and the slave decodes the message properly. The SVI message source must know how its encapsulation will build the message and also know how the receiving SVI encapsulation will interpret the data words in the message.
Typically, users encode the data in the message in software on the originating processing element. However, for low-latency operation, the message building can be done in hardware. The existing commands include those functions needed to implement SVI encapsulations envisioned to date; more commands may be necessary in the future to support new interconnects with unusual multi-processor or cache support requirements. Users can easily add commands, providing previous encapsulations with access to the new SVI commands.
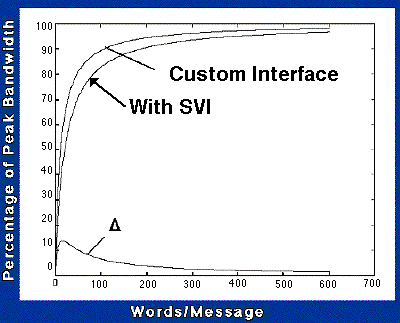
To supplement the signal/timing/protocol definition and support end users" modeling efforts, the appendix to this application note contains VHDL code templates for SVI encapsulations. These templates include the entities and architectures a designer would typically need to code an encapsulation. In section 4.4, links to the VHDL code for several of the encapsulations performed as part of the verification study are provided. The code provided for the HOTLink encapsulation and the encapsulated RNI bridge are executable provided the reader has access to the Synopsys Logic Modeling's Smart Model library. To date, LM/ATL has implemented several SVI encapsulations. An interoperability demonstration has been developed in which two processing elements, a custom vector processor and several interconnect fabrics (PCI, RACEway, Myrinet and one sensor interface (HOTLink)) were encapsulated. Several combinations of the processing elements and interconnects were then mixed and matched to demonstrate interoperability. The results, as shown in Figure 4 - 4 for an SVI encapsulated PCI bus versus a custom interface, demonstrate the ability to provide plug and play interconnect between different elements with minimal performance impact. In this configuration, for data transfers of more than 256 elements, the performance impact is less than 5% of peak bandwidth.
In summary, the SVI is a critical element of the RASSP model-year architecture; it guides users in developing architecture elements that can be easily reused and upgraded. It must be used prudently, balancing the immediate performance impact against the future ability to upgrade to a new processing node, internal or external interconnect fabric.
The RNI consists of 2 encapsulated fabric interfaces on either side of an encapsulated bridge element. The fabric interfaces implement the two specific interfaces to the interconnect fabrics. The bridge may be between an internal and an external interconnect fabric or a it may be between two external interconnect fabrics. The actual bridging function is performed by the RNI bridge element, which consists of a buffer memory to facilitate asynchronous coupling between the two interfaces, and a controller which coordinates data transfers and provides flow control. The bridge element can be implemented via custom logic (e.g. FPGA, ASIC) or a programmable processor.
As in the case of Internal Module interface, a layered communication approach is employed. Since the RNI provides a bridge between two interfaces, two separate OSI-layered structures exist at each interface. The lowest layers of the two protocols are translated in the Fabric Interface components. The higher levels of each protocol are translated within the RNI bridge element and converge when the data interchange is stripped of all its interface specific identity, and exists as a pure SVI message on the SVI protocol. Again, the ISO/OSI model is being used as a reference and does not imply that the layering ultimately employed in defining the internal node architecture will strictly follow this model or implement all seven layers. An example of an encapsulated RNI bridge is described in [ Myri_PCI]. This model is executable if the user has access to the Synopsys Logic Modeling's SmartModel Library.
The exact implementation of the RNI itself depends on the type of interfaces being served. The RNI to implement interfaces for loosely coupled processing subsystems, operator consoles, and certain types of ancillary equipment will have one implementation, while the RNI to support a remote sensor application will have another. As mentioned above, the complexity of the data transfer protocol may also have a wide variance. A sensor or multidrop bus would generally require a fairly simple protocol supported by a relatively simple hardware controller within the RNI bridge element. This type of RNI is referred to as a simple RNI. On the other hand, a local area network application most likely would require a programmable processor to implement a more complex software-based protocol. This type of RNI is referred to as a complex RNI. More than one class of RNI will be required to support all aspects of signal processor interfacing. As described in Section 7, the RNI will be supported through various object subclasses or derived classes for Fabric Interfaces, both internal and external, and RNI Bridge Elements, within the reuse library.
Several encapsulations were done for the Model Year Architecture Hardware Verification effort. These include encapsulations of internal nodes, multidrop buses, sensors and networks. First, how to determine which architectural interfaces to encapsulate will be discussed. Following that there is a short description of the encapsulations which have been performed at LM/ATL. At the end of each description is a link to the complete application note for each encapsulation.
To apply the Model Year Architecture, the designer performs the following steps:
There are basically three places to look for upgradeable interfaces as shown in Figure 4 - 6.
If a similar design is found, modify it to meet new requirements. If not, start with templates. The templates contain entities and architectures for the SVI. They lend structure to the encapsulations, so that even though different people may design the encapsulations, they will all look somewhat the same, making them more easily reusable. They are available at [SVI-Template]
The savings comes when the internal node or the fabric interface is upgraded, which is the second aspect of the development time. For example, assume there exists an encapsulated internal node and an encapsulated fabric interface, and that the designer is upgrading the internal node. The encapsulated fabric interface remains essentially the same, and the new node is encapsulated. It is anticipated that this will take less time than doing another custom interface because it is not necessary to write new drivers for the fabric interface. It is also not necessary to learn the protocol of the fabric interface. Furthermore, once the new internal node is encapsulated, it can be interfaced to any other encapsulated fabric interface. If there are 10 encapsulated interfaces, one needs only to encapsulate the internal module once to interface it to all of the fabric interfaces. If all of the interfaces were custom interfaces, one would need to design 10 different custom interfaces to achieve the same result. Clearly, this reduction in the number of integrations required from the order of N2 to N equates to a significant savings in development time.
4.0 Implementation of the Functional Architecture Standard Virtual Interface (SVI) and Reconfigurable Network Interface (RNI)
4.1 Model-Year Hardware Interoperability
4.2 Standard Virtual Interface (SVI)
The SVI defines a construct which makes it easier for users to implement node-level interoperability and to upgrade various architectural-level reuse elements, such as processor nodes and interface elements, by defining a standard interface encapsulation procedure. The SVI is a critical element of the RASSP model-year architecture. It guides users in developing architecture elements that can be easily reused and upgraded. In the past, integrating an internal node, which may contain several processing elements on a processor bus, to a specific interconnect was performed as a specialized implementation; this point-to-point integration approach can lead to a total of N2 possible integrations for N nodes and interconnects. The intent of the SVI is to provide a common functional interface for all of these integrations, greatly reducing the number of integrations required. Once a node has been integrated to the SVI standard, users can integrate it to any interconnect integrated to this standard. This approach provides a level of plug and play interoperability that has never before been realized. The SVI is a functional, not physical, interface specification that supports technology independence - the 'virtual' in SVI.
4.4 MYA Application Example
4.4.1 Introduction
4.4.2 Approach
4.4.2.1 Select the high payoff interfaces for encapsulation
The first key step in applying the Model Year architecture is to take the candidate implementation and evaluate the different types of communications interfaces of the Functional Architecture to determine: what interfaces are at the periphery of modules that will require regular upgrading?
4.4.2.2 Research existing encapsulations to find examples that are similar to new design
For the Model Year Architecture implementation, the first step would be to search the Reuse Library for available encapsulations. Through the course of the verification studies, it has been found that the process of designing a new encapsulation is simplified by modifying or at least referring to a similar existing one. There are architectures and portions of architectures, such as case structures in existing encapsulations, that are often able to be used again with only slight modifications. The following sections describe the different types of encapsulations and links to available code. Not all of the encapsulations can be executed by the reader due to the proprietary nature of some of the underlying models. Nevertheless, portions of the model may be reusable.
4.4.2.3 Use of templates
4.4.2.4 Develop and validate the Virtual Prototype Implementation
The tools used to support this detailed design and synthesis by the RASSP team include the following. Other similar vendor tools may be substituted and should achieve the same results.
4.5 Validation Techniques
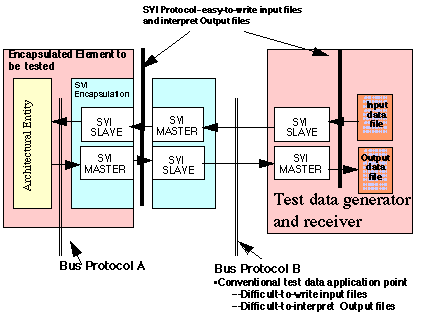
It is often difficult, on the one hand, to generate data in the format required by some protocols and, on the other hand, to interpret data generated by some protocols. To alleviate this problem, LM/ATL has used the encapsulations to input and output the data. That is, once an encapsulation is completed, the slave encapsulation can be used to supply data to the model and the master to extract data from the model. Normally, the slave translates the SVI protocol into the interface protocol. Referring to Figure 4 - 9, it is clear how the slave can be used to supply data to the network and the master, to extract it. The user can supply an SVI data set which is very easy to develop, to any encapsulation, and also have the output supplied in the easily readable SVI format
4.6 Development Time
The difference in developing the hardware for a MYA compliant interface compared to developing the hardware for a custom interface has two aspects. The first is the actual time it takes to develop the interface. In the case of the MYA, the first time an interface is designed, it is necessary to encapsulate either an internal node or fabric interface and whatever that node or fabric interface is connected to. This will generally take longer than a custom interface, since two interfaces are being designed.
![]()
![]()
![]()
![]()
Next: 5 Emerging Interface Standards Overview
Up: Appnotes Index
Previous: 3 Model Year Functional Architecture Technology